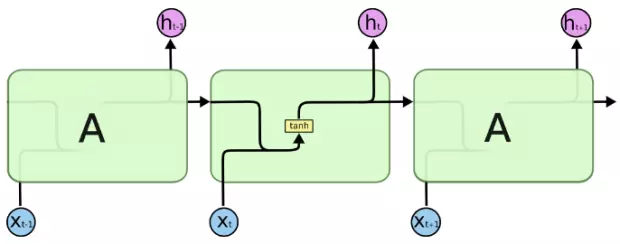
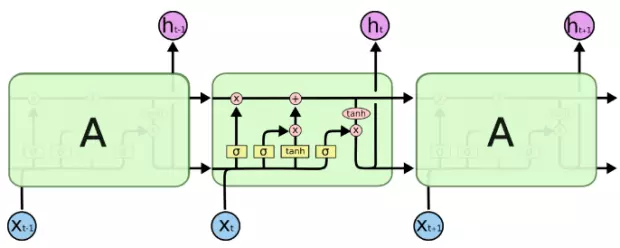
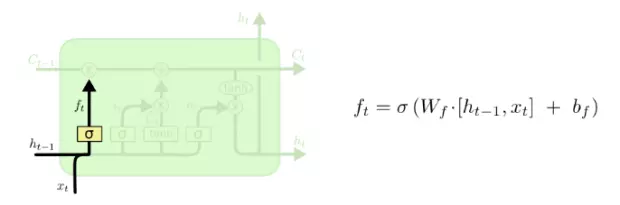
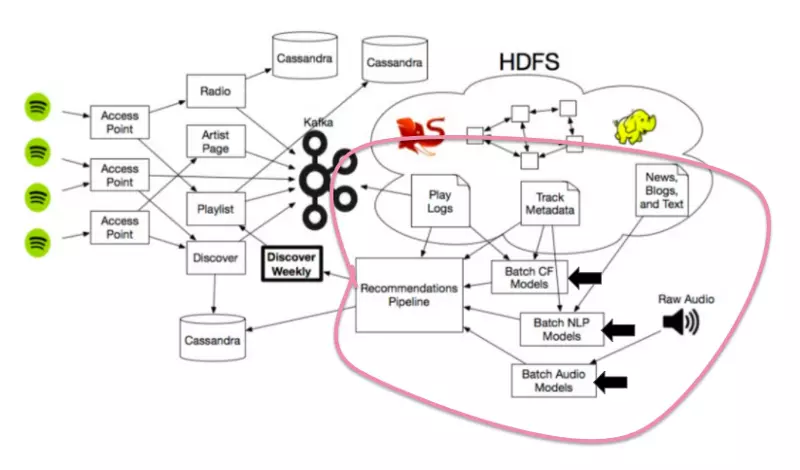
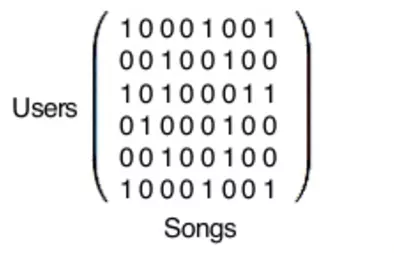
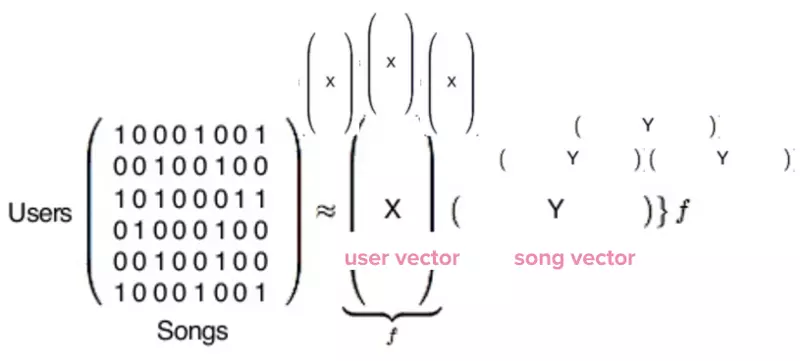
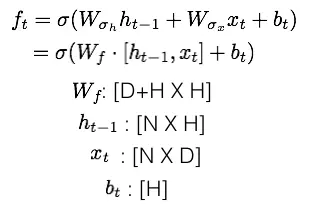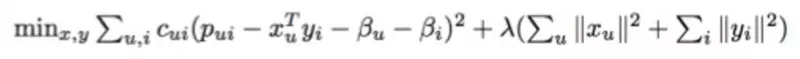An awesome paper introduction will catch one's eyes and it is benefit
to organize the rest of paper.
Do a simple introduction of what I did and the things I did will
improve which related domain's work.
For example, the section of introduction can splice into 4
paragraphs:
First paragraph introduce meaning of paper and some related works (as
a short literature review);
Second paragraph present my innovation of this paper, such as which
newest methods I have using, or which feature no one used;
Third paragraph do a summary for previous;
Fourth paragraph display a summary of results, showing that this
paper got an 'state-of-the-art' result comparing to baseline.
Fifth paragraph educe the rest of paper. A canonical 'fifth
paragraph' as follow:
The rest of this paper is organized as follows. Section 2 gives an
overview of the theory behind tree edit distance algorithms, the basis
of our work. Section 3 presents our improved tree structure analysis
algorithm, while Section 4 shows the application of this algorithm in
the various tasks that comprise our approach. Experimental results
demonstrating the effectiveness of our approach are in Section 5.
Section 6 discusses related work. Finally, conclusions and directions
for future work can be found in Section 7.
Previous paragraph cites: Reis D C, Golgher P B, Silva A S, et al.
Automatic web news extraction using tree edit distance[C]//
International Conference on World Wide Web. ACM, 2004:502-511.
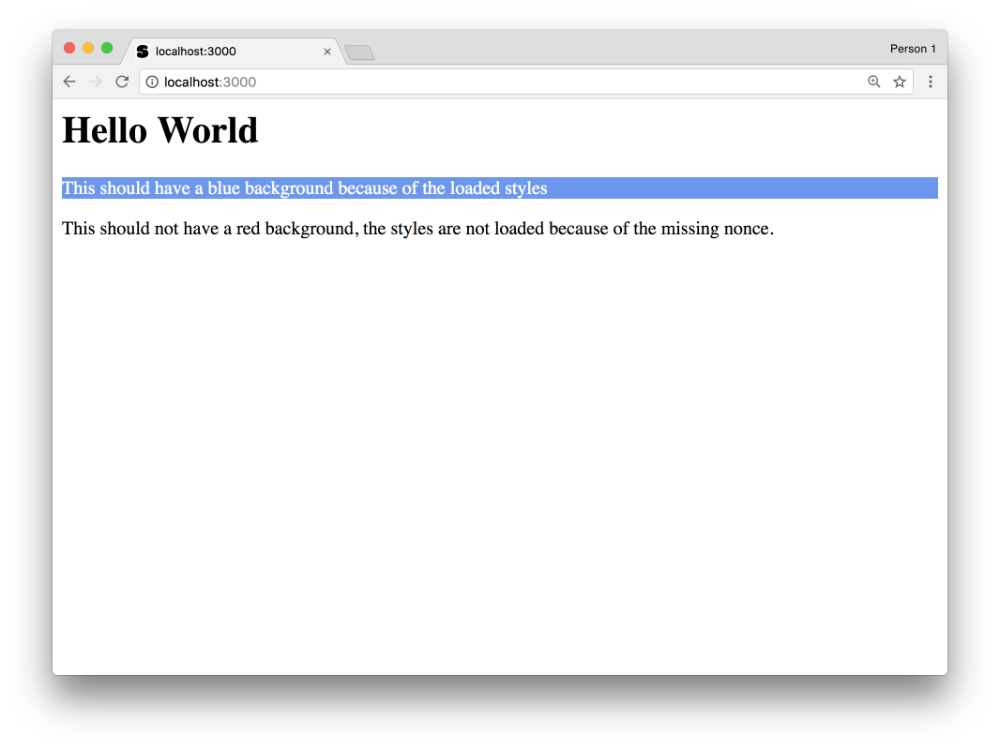
app.get('/', (req, res) => { res.send(` <h1>Hello World</h1> <style nonce=${req.nonce}> .blue { background: cornflowerblue; color: white; } </style> <p class="blue">This should have a blue background because of the loaded styles</p> <style> .red { background: maroon; color: white; } </style> <p class="red">This should not have a red background, the styles are not loaded because of the missing nonce.</p> `); });
app.listen(PORT, () => { console.log(`Listening on http://localhost:${PORT}`); });
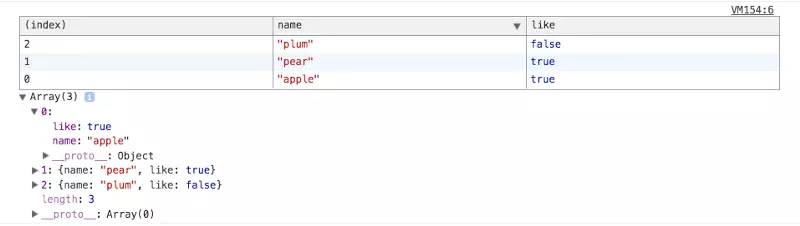
它们的实现方式取决于浏览器。在最开始的时候,规范中建议 dir
要保持对对象的引用,而 log 不需要引用。(Log
会显示一个对象的副本)。但现在,如上图所示,log
也保持了对于对象的引用。它们展示对象的方式有所不同,但我们不再加以深究。不过
dir 在调试 HTML 对象的时候会非常有用。 > 译注:console.dir
会详细打印一个对象的所有属性与方法。
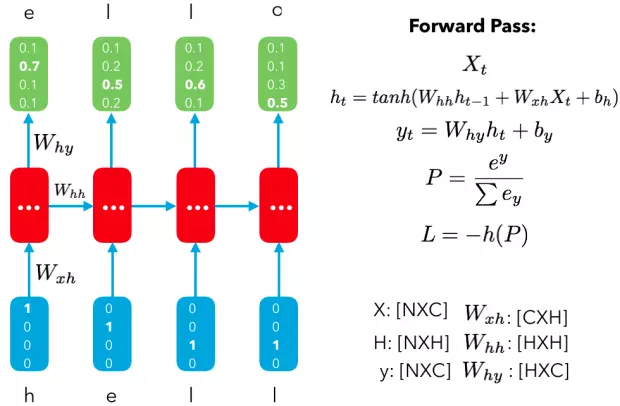
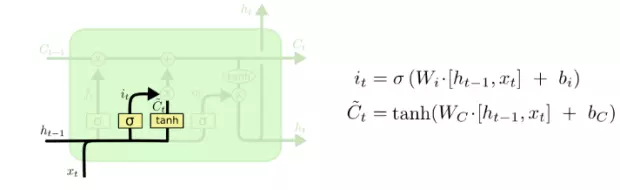
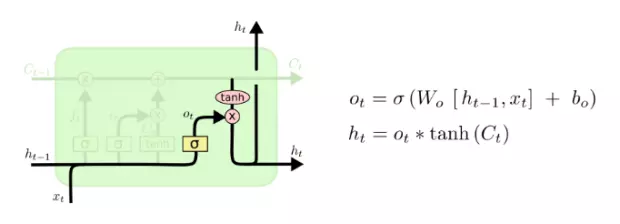
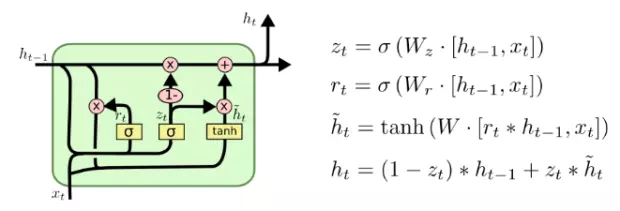
def__call__(self, inputs, state, scope=None): """Gated recurrent unit (GRU) with nunits cells.""" with vs.variable_scope(scope ortype(self).__name__): # "GRUCell" with vs.variable_scope("Gates"): # Reset gate and update gate. # We start with bias of 1.0 to not reset and not update. r, u = array_ops.split(1, 2, _linear([inputs, state], 2 * self._num_units, True, 1.0)) r, u = sigmoid(r), sigmoid(u) with vs.variable_scope("Candidate"): c = self._activation(_linear([inputs, r * state], self._num_units, True)) new_h = u * state + (1 - u) * c return new_h, new_h