RNN 循环神经网络系列 5: 自定义单元
本系列文章汇总
- RNN 循环神经网络系列 1:基本 RNN 与 CHAR-RNN
- RNN 循环神经网络系列 2:文本分类
- RNN 循环神经网络系列 3:编码、解码器
- RNN 循环神经网络系列 4:注意力机制
- RNN 循环神经网络系列 5:自定义单元
在本文中,我们将探索并尝试创建我们自己定义的 RNN 单元。不过在此之前,我们需要先仔细研究简单的 RNN,再逐步深入较为复杂的单元(如 LSTM 与 GRU)。我们会分析这些单元在 tensorflow 中的实现代码,最终参照这些代码来创建我们的自定义单元。本文将援引由 Chris Olah 所著,在 RNN、LSTM 方面非常棒的一篇文章中的图片。在此我强烈推荐你阅读这篇文章,本文中会重申其中许多相关内容,不过由于我们主要还是关注 tf 代码,所以这些内容将会较快地略过。将来当我要对 RNN 结构进行层规范化时,我还会引用本文中的代码。之后的文章可以在这儿查看。
基本 RNN:
对于传统的 RNN 来说,最大的问题就在于每个单元的重复输入都是静态的,因此我们无法充分学习到长期的依赖情况。你回想一下基本 RNN 单元,就会发现所有操作都是单一的 tanh 运算。
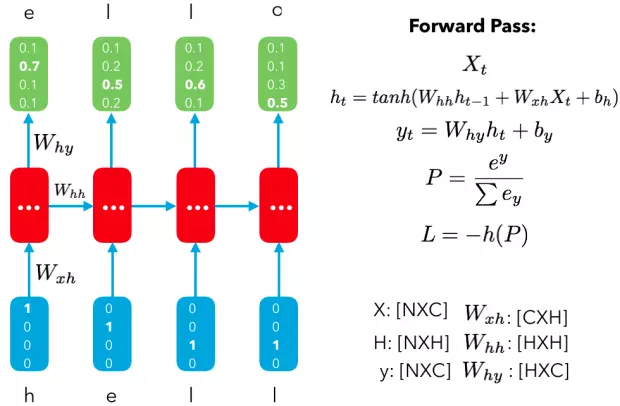
对于解决短期依赖情况的问题来说,这种结构已经够用了;但如果我们希望通过有效的长期记忆来预测目标,则需要使用更稳定强大的 RNN 单元 —— LSTM。
长短期记忆网络(LSTM):
LSTM 的结构可以让我们在更多的操作中进行长期的信息控制。传统的 RNN 仅有一个输出,其既作为隐藏状态表示也作为此单元的输出端。
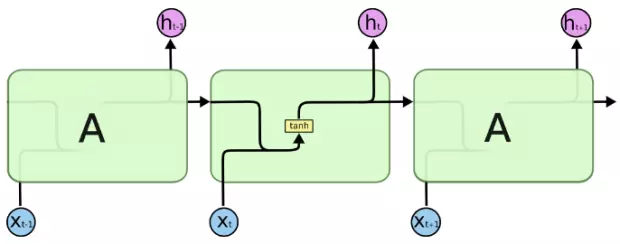
这种结构缺乏对信息的控制,无法存住对许多步之后有用的信息。而 LSTM 有两种不同的输出。其中一种仍与前面的传统结构一样,既作为隐藏状态表示也作为单元输出;但 LSTM 单元还有另一种输出 - 单元状态 C。这也是 LSTM 精髓所在,让我们仔细研究它。
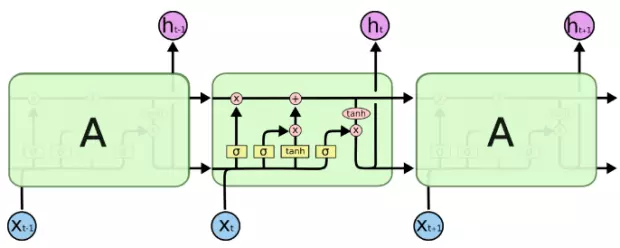
遗忘门:
第一个要介绍的门就是遗忘门。这个门可以让我们选择性地传递信息以决定单元的状态。我将公式罗列在下,后面介绍其它的门时也会如此。
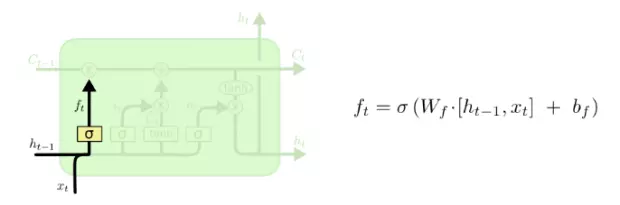
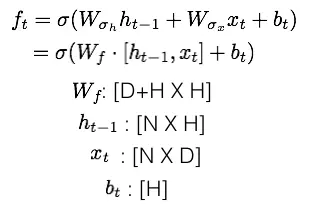
你可以参考类似 tf 的 _linear 函数来实现它。不过遗忘门的主要要点是对输入与隐藏状态前应用了 sigmoid。那么这个 sigmoid 的作用是什么?请回想一下,sigmoid 会输出在 [0, 1] 范围的值,在此我们将其应用于 [N X H] 的矩阵,因此会得到 NXH 个 sigmoid 算出的值。如果 sigmoid 得到 0 值,那么其对应的隐藏值就会失效;如果 sigmoid 得到 1 值,那么此隐藏值将会被应用在计算中。而处于 0 和 1 之间的值将会允许一部分的信息继续传递。这样就能很好地通过阻塞与选择性地传递输入单元的数据,以达到控制信息的目的。
这就是遗忘门。它是我们的单元得到最终结果前的第一个步骤。下面介绍另一个操作:输入门。
输入门:
输入门将获取我们的输入值 X 以及在前面的隐藏状态,并对它们进行两次运算。首先会通过 sigmoid 门来选择性地允许部分数据输入,接着将其与输入值的 tanh 值相乘。
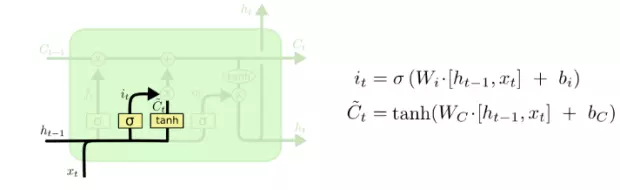
这儿的 tanh 与前面的 sigmoid 操作不同。请回忆一下,tanh 会将输入值改变为 [-1, 1] 范围内的值。它本质上通过非线性的方式改变了输入的表示。这一步与我们在基本 RNN 单元中进行的操作一致,不过在此我们将两值的乘积加上遗忘门得到的值得到本单元的状态值。
遗忘门与输入门的操作可以看做同时保存了旧状态(C_{t-1})的一部分与新变换(tanh)单元状态(C~_t)的一部分。这些权重将会通过我们数据的训练学到需要保存多少数据以及如何进行正确的变换。
输出门:
最后一个门是输出门,它利用输入值、前面的隐藏状态值以及新单元状态值来共同决定新隐藏状态的表示。
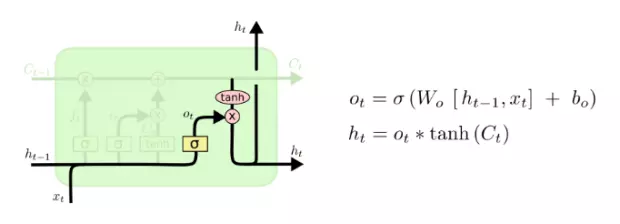
该步骤依旧涉及到了 sigmoid,将它的值与单元状态的 tanh 值相乘以决定信息的去留。需要注意这一步的 tanh 计算与输入门的 tanh 计算不同,此步不再是神经网络的计算,而仅仅是单纯、不带任何权重地计算单元状态值的 tanh 值。这样我们就能强制单元状态矩阵 [NXH] 的值处于 [-1, 1] 的范围内。
变体
RNN 单元有许多种变体,在此再次建议去阅读 Chris Olah 的这篇博文学习更多相关知识。不过他在文中讨论的是 peehole 模型(在计算 C_{t-1} 或 C_t 时允许所有门都能观察到单元状态值)以及单元状态的 couple(更新与遗忘同时进行)。不过目前 LSTM 的竞争对手是正在被广泛使用的 GRU(Gated Recurrent Unit)。
GRU(Gated Recurrent Unit):
GRU 的主要原理是将遗忘门与输入门结合成一个更新门。
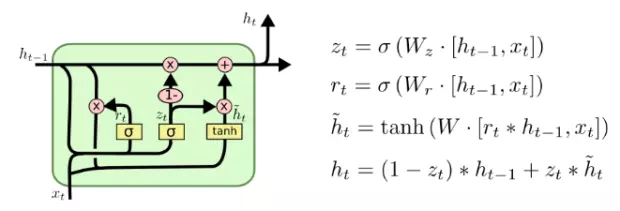
在实际使用中,GRU 的性能与 LSTM 相当,但其计算量更小,因此它现在日益流行。
原生 Tensorflow 实现:
我们先观察一下 Tensorflow 官方对于 GRU 单元的实现代码,主要关注其函数调用方式、输入以及输出。然后我们会复制它的结构用于创建我们自己的单元。如果你对其它的单元有兴趣,可以在这儿找到它们的实现。本文将主要关注 GRU,因为它在大多数情况下性能与 LSTM 相当且复杂度更低。
1 | class GRUCell(RNNCell): |
GRUCell 类由 init 函数开始执行。在 init 函数中定义了单元的数量与其使用的激活函数。其激活函数一般是 tanh,不过也可以使用 sigmoid 来使得值固定在 [0, 1] 范围内方便我们控制信息流。另外,它还有两个在调用时会返回 self._num_units 的属性。最后定义了 call 函数,它将处理输入值并得出新的隐藏值。回忆一下,GRU 没有类似 LSTM 的单元状态值。
在 call 中,我们首先计算 r 和 u(u 是前面图中的 z)。在这步中,我们没有单独去计算它们,而是以乘以 2 倍 num_units 的形式合并了权重,再将结果分割成两份得到它们(split(dim, num_splits, value))。然后对得到的值应用 sigmoid 激活函数,以选择性地控制信息流。接着计算 c 的值,用它计算新隐藏状态表示值。你可能发现它计算 new_h 的顺序和之前颠倒了,不过由于权重会同时进行训练,因此代码仍能正常运行。
其它的单元代码都与此代码类似,你弄明白了上面的代码就能轻松解释其它单元的代码。
本文发布于掘金 https://juejin.im/post/59fbd28b6fb9a045204b91f2