Spotify 每周推荐功能:基于机器学习的音乐推荐
在每周周一,超过 1 亿位 Spotify 用户会收到一份新鲜的歌曲播放列表。这个自定义列表中包含了 30 首用户从来没听过,但可能会喜欢上的歌曲。这个神奇的功能被称为“每周推荐(Discover Weekly)”。
我是 Spotify 的忠实粉丝,尤其喜欢它的每周推荐功能。因为,它让我感觉到我被重视着。它比谁都了解我的音乐品味,而且每周的推荐都刚好令我满足。如果没有它,我可能一辈子都找不到一些我非常喜欢的歌曲。
如果你苦于找不到想听的音乐,请让我隆重介绍我最好的虚拟伙伴:
事实证明,痴迷于每周推荐的用户不仅只有我一个 —— 许多用户都为它痴狂,这足以让 Spotify 重新思考其发展重点,将更多的资源投入播放列表推荐算法中。
每周推荐功能于 2015 亮相,从那时开始,我就非常渴望了解它是如何运作的(我是他们公司的粉丝,所以常常假设自己在 Spotify 工作并研究他们的产品)。在经过三个星期的疯狂搜索之后,我得以瞟到了其帷幕后的一丝真容。
那么 Spotify 是如何做出每周为每个用户选出 30 首歌这个惊人的工作的呢?让我们先看一看其它一些音乐服务商是如何进行音乐推荐的,然后分析为什么 Spotify 做的更好。

早在 2000 年,Songza 就开始使用人工编辑来进行在线音乐策展(curation,策划并展示)。“人工编辑”意味着需要一些”音乐专家“团队或者其它管理员手动将他们认为很好听的歌放到歌单中去。(后来 Beats Music 也实行了同样的策略)。虽然人工编辑运作的很好,但是它需要手动操作并且过于简单,无法考虑到每个听众个人音乐品味的差别。
如 Songza 一样,Pandora 也是音乐策展的元老之一。它采用的方法较为先进,使用人工标注歌曲属性的方法。也就是说,有一组人在听歌之后,为每首歌选择一些描述性的词,对各个曲目进行了标注。然后,Pandora 就能利用代码简单地对标注进行筛选,得到比较类似的歌单。
与此同时,麻省理工学院媒体实验室开发出了名为”The Echo Nest“的智能音乐助手,开创了一种更加先进的个性化音乐推荐方式。The Echo Nest 使用算法分析各个音乐音频与文本的内容,使其能进行音乐识别、个性化推荐、创建歌单以及进行分析。
此外,至今依然存在的 Last.fm 采用了一种名为协同过滤的不同的方法。它可以识别用户可能喜欢的音乐。稍后会详细提到它。
以上就是其它音乐策展服务进行推荐的方法。那么 Spotify 是如何造出它们神奇的引擎,如何做出更加符合用户口味的推荐的呢?
Spotify 的 3 种推荐模型
实际上 Spotify 并没有使用某个革命性的推荐模型 —— 与此相反,他们是将一些其它服务中单一使用的最佳策略混合起来,创建了自己独特、强大的发现引擎。
Spotify 每周推荐的开发者主要采用了如下三种类型的推荐:
- 协同过滤模型(就是 Last.fm 最开始使用的模型),通过分析你的行为与他人的行为进行运作。
- 自然语言处理(NLP)模型,用于分析文本。
- 音频 模型,用于分析原始音轨。
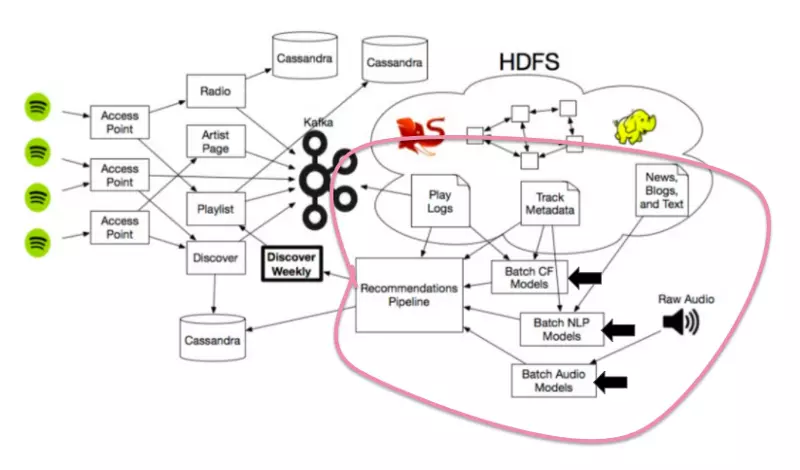
下面让我们深入了解上述各个推荐模型吧!
推荐模型 #1:协同过滤

首先简述一些背景:当人们听见”协同推荐“这个词的时候,大多会想起 Netflix 这个首批采用协同过滤推荐模型的公司。他们使用用户对影片的评星来确定将什么影片推荐给其它喜好相似的用户。
当 Netflix 成功使用这种推荐方法之后,开始迅速发展。现在通常被认为是尝试使用推荐模型的鼻祖。
与 Netflix 不同,Spotify 没有让用户对音乐进行评星。他们采用的数据是隐式反馈 —— 具体来说,包括对用户听歌的流数据进行统计,以及收集一些其它的流数据,包括用户是否将歌曲保存到他们自己的歌单、在听完歌之后是否访问了歌手的主页等等。
那么什么是协同过滤,它又是如何运作的呢?这儿用下面这个简短的对话来做个简述:

图中发生了什么?图中的两个人都有一些喜欢的歌曲 - 左边的人喜欢歌曲 P、Q、R 及 S;右边的人喜欢歌曲 Q、R、S 及 T。
协同过滤就像用这些数据说:
”Emmmmm,你们都喜欢 Q、R、S 三首歌,所以你们可能是类似的用户。所以,你应该会喜欢对方爱听而你还没听过的歌。“
也就是说,会建议右边的人去听歌曲 P 试试,建议左边的人去听听歌曲 T。这很简单吧!
但 Spotify 是如何将这种方法落到实处,用于由百万级别用户的喜好歌曲来计算百万级别用户的推荐的呢?
……应用数学矩阵,然后使用 Python 库来实现。
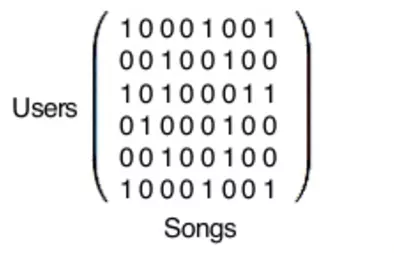
在实际情况中,你在看到的这个矩阵是巨大无比的,矩阵中的每一行都代表了 Spotify 的 1.4 亿用户(如果你也用 Spotify,那你也会是这个矩阵的一行),每列代表了 Spotify 数据库中的 3000 万首歌。
接着,Python 库会长时间、缓慢地对矩阵按照以下分离公式进行计算:
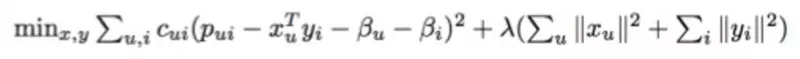
在它完成计算之后,我们会得到两种向量,在这里用 X 与 Y 表示。X 是用户向量,代表了单个用户的口味;Y 是歌曲向量,代表了一首歌的属性。
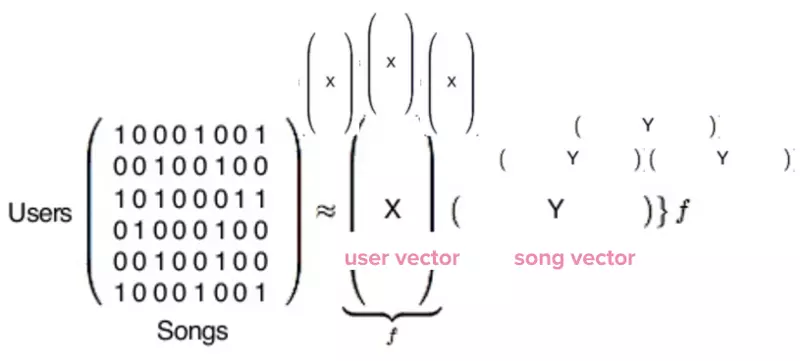
现在,我们有了 1.4 亿条用户向量以及 3000 万条歌曲向量。这些向量的内容实质上就是一堆数字,本身没有任何意义。但是对它们进行对比就能起到巨大的作用。
为了找到哪些用户和我有着最相似的口味,协同过滤会将我的向量和其它每个用户的向量进行对比,最终找到与我最相近的用户。同样的,对 Y 向量进行比较,可以找到与你正在听的歌最相近的歌。
协同过滤的效果相当不错,但 Spotify 没有满足于此,他们知道通过增加一些其它的引擎可以使得效果更好。下面让我们看看 NLP。
推荐模型 #2:自然语言处理(NLP)
Spotify 采用的第二种推荐模型是自然语言处理(NLP)模型。顾名思义,这种模型的数据来源就是传统意义上的文字 —— 这些文字来源于歌曲的元数据、新闻文章、博客,以及互联网中的其它文本。

NLP 是一种让计算机理解人类语言的能力,是一个庞大的领域。在这儿可以采用一些情感分析 API 来实现。
NLP 背后的机制已经超出了本文的讨论范围。不过我们可以这么来大致概括:Spotify 爬虫不断地查找与音乐有关的博客以及各种文本,并了解人们对特定艺术家及歌曲的看法 —— 谈到这些歌曲人们通常会用什么形容词和语言,以及会同时提到哪些其他的艺术家及歌曲。
虽然我不知道 Spotify 处理数据的细节,但我知道 the Echo Nest 是如何与他们进行协同工作的。他们会将语言处理封装为“文化向量”或者“高频短语”。每个艺术家及歌曲都有着数以千计的高频短语,且每天都在变化。每个短语都有一个权重,用于表示这个短语的重要性(大致来说,就是某人描述这个音乐时会用这个短语的概率)。

the Echo Nest 使用的“文化向量”与“高频短语”,Brian Whitman 提供表格
接下来与协同过滤一样,NLP 模型会使用这些短语和权重为每首歌构建一个表示向量,这样就能判断两首歌是否相似了。酷不酷炫?
推荐模型 #3:原始音频模型
在开始本章之前,你可能会问:
我们已经在前两个模型中应用了足够多的数据,为什么还需要分析音频本身呢?
首先,引入这第三个模型能使这个惊人的推荐服务的准确率得到进一步的提升。但实际上,使用这个模型还有第二种目的:与前两个模型不同,原始音频模型可以用于处理新歌。
举个例子,你的歌手朋友将他的新歌传上了 Spotify,然而他仅有 50 名听众,如果要使用协同过滤显然人数太少了。并且他还没有火起来,在互联网上任何角落都没有被提到过,因此 NLP 模型也没法为他发挥作用。不过幸运的是原始音频模型不会在乎这是新歌还是老歌,有了它的帮助,你朋友的歌就有可能和那些流行的歌一起被加入每周推荐歌单了!
接下来解释“如何”对如此抽象的原始音频进行分析。
…使用 卷积神经网络(CNN)!
卷积神经网络正是人脸识别背后使用的技术。在 Spotify 这个场景中,工程师们使用音频数据来代替像素。下面是神经网络一中结构的实例:
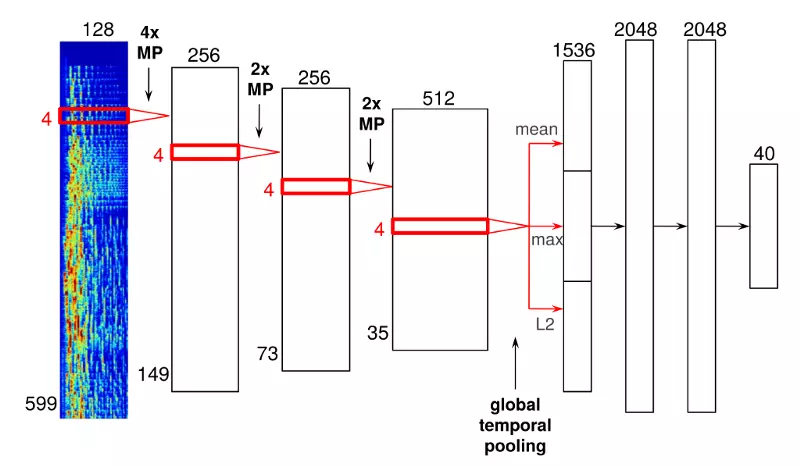
这个特制的神经网络有 4 层卷积层,它们在图的左边,看起来像很厚的木板;它还有 3 层全连接层,它们在图的右边,看起来像很窄的木板。输入值是音频帧的频率的表示,在图中以光谱图的形式表示。
音频帧通过这些卷积层后,在最后一个卷积层边你可以看到一个“全局时间池化”层。这个池化层沿整个时间轴进行池化,高效地根据统计学找出在歌曲的时间序列中找到的特征。
在此之后,神经网络会输出它对一首歌的理解,其中包括各种类似时间戳、调性、风格、节奏、音量等典型特征。下图为 Daft Punk 的 “Around the World” 一曲中截取 30 秒片段的数据。
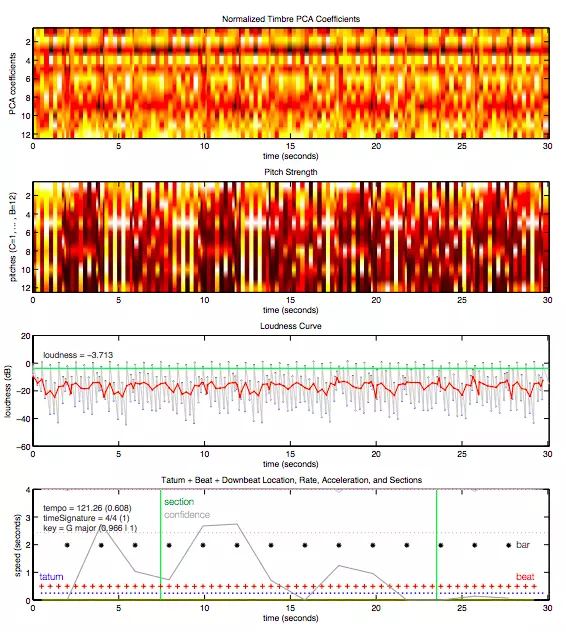
图片版权:Tristan Jehan & David DesRoches (The Echo Nest)
最终,这些由一首歌理解到的各种关键的信息可以让 Spotify 理解不同的歌中的一些本质的相似之处,由此基于用户的听歌历史推断出此用户可能会喜欢这首新歌。
以上概况了推荐模型中的三个基本组成部分。正是由这些推荐模型组成的推荐 pipeline,最终构成了强大的每周推荐歌单功能!
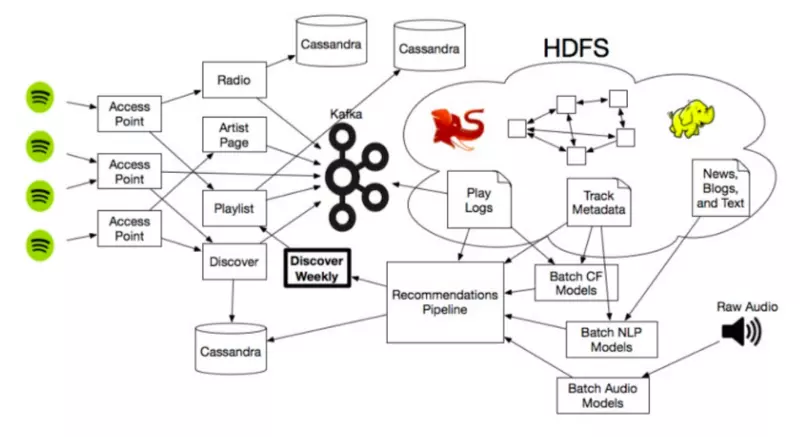
当然,这些推荐模型还与 Spotify 更大的生态系统息息相关,这个生态系统中包含了海量的数据,使用大量的 Hadoop 集群对推荐系统践行规模化运作,使得这些引擎能够在大尺度、无穷尽的互联网中顺利地分析音乐相关文章以及无比庞大的音频文件。
我希望本文的信息能满足你的好奇心(就像我的好奇心被满足了一样)。现在我正在通过我个性化的每周推荐找到我喜欢的音乐,了解以及欣赏它背后的各种机器学习知识。🎶
**资源: - From Idea to Execution: Spotify’s Discover Weekly (Chris Johnson, ex-Spotify) - Collaborative Filtering at Spotify (Erik Bernhardsson, ex-Spotify) - Recommending music on Spotify with deep learning (Sander Dieleman) - How music recommendation works — and doesn’t work (Brian Whitman, co-founder of The Echo Nest) - Ever Wonder How Spotify Discover Weekly Works? Data Science (Galvanize) - The magic that makes Spotify’s Discover Weekly playlists so damn good (Quartz) - The Echo Nest’s Analyzer Documentation
本文发布于掘金 https://juejin.im/post/59fbd0d9518825299a468a8b