Slide of "AtTGen: Attribute Tree Generation for Real-World Attribute Joint Extraction"
事件抽取(Event Extraction)是一种面向非结构化文本或半结构化数据的信息抽取(Information Extraction)任务,与传统面向知识图谱的实体、关系、属性等信息抽取有所不同的是,事件抽取抽取的是"事件",即某些事物在时空范围内的运动。在 ACE(Automatic Content Extraction)测评会议中,事件被描述成: "在特定时间内,发生的,同时有参与者的,存在状态变化的事情。例如,"李主任将在明天举办的大会上发言"中描述了具体的事件,这样的句子也被称为事件提及,包含了"李主任"-"大会"-"发言"这些事件要素。而事件抽取的目的,正是从非结构化、半结构化的事件提及中将结构化的事件要素提取出来从而进行分析。事件抽取是不少任务的前置模块,对于事理图谱构建、情报分析、新闻摘要、自动问答等任务均有着重要的作用,事件抽取的准确程度也会显著地影响后续任务的效果。
一般来说,根据是否有明确的、事先定义好的事件模式(或事理图谱 schema),可以将事件抽取分为封闭域事件抽取(Close-domain Information Extraction,也有称为限定域事件抽取)与开放域事件抽取(Open-domain Information Extraction)。封闭域事件抽取的主要任务包括:
根据上述不同事件抽取任务得到的数据,可以明确地描述一个具体的事件。一个完整的封闭域事件抽取系统,应当以联合模型(Joint Model)或抽取流水线(Pipeline)的形式得到上述的内容,或者至少得到触发词、论元。以一个具体的例子展示封闭域事件抽取:"詹姆斯枪击了弗兰克"中,包含攻击类型的事件,其触发词为枪击,事件论元包含詹姆斯和弗兰克,前者的论元角色是攻击者,后者的论元角色是被攻击者。
而开放域事件抽取与封闭式事件抽取不同,没有明确的事件模式或 schema,因此构建开放域事件抽取不拘泥于精确地将事件具体要素进行精确抽取,其主要目的一般是通过聚类、文本语义分割等无监督手段,在开放的文本数据中分析、检测出事件,以供后续的分析。开放域事件抽取在舆情感知、舆情分析、情报分析、股市情绪调研等应用中有着重要的作用。开放域事件抽取的主流任务基本可分为:
由于开放域事件抽取并没有像 ACE 那样公认、权威的任务范式,因此上述分类可能根据实际应用场景、数据集等条件产生变动。但一般来说,开放域事件抽取的粒度较粗,一般不会对具体的触发词类型、论元角色层面的信息进行抽取。
本文中主要对封闭域事件抽取进行简述。
Enhancing Chinese Pre-trained Language Model via Heterogeneous Linguistics Graph 一文是我和组内同学合作的工作,录用于 ACL 2022 主会。代码已在 GitHub开源,ppt可在这里查看。
这篇论文提出了一种用于表达中文字-词-句语言学结构关系的异质图(Heterogeneous Linguistics Graph, HLG)。并利用图神经网络建模,在该HLG异质图上实施多步信息传播(Multi-Step Information Propagation, MSIP)以在预训练语言模型的微调阶段训练神经网络的参数。使用这样的HLG建模中文自然语言的结构可以自然而有效地引入分词结构化信息,从而提升原生预训练语言模型在中文上的效果,实验证明该方法在多个基准数据集上得到了稳定的提升。同时,相比起前人发表在ACL 2020年的工作[1](MWA),此论文使用的MSIP和HLG建模在训练、推理速度上有着明显的优势,在不降低性能的情况下提升了约7倍的训练与推理速度。
近年来,以BERT为代表的预训练语言模型方法在各个NLP任务中得到了广泛的应用。典型的预训练语言模型应用方法可以归结为预训练-微调两阶段模式,即先通过在大规模无标注语料库上进行无监督、自监督预训练,然后通过监督训练迁移到具体的下游任务中使用。而针对中文自然语言处理,研究者们提出了各类适配中文语言特性的预训练语言模型,如ERNIE[2]、Glyce[3]等,尽可能利用中文本身的一些性质(例如中文分词、中文字形等)来提升预训练任务的效果。Li等人[1]基于向预训练语言模型融入中文分词的动机提出了MWA模型,试图向原生的预训练语言模型中融入词汇级别特征,与其它专注于预训练的工作不同的是,MWA是在微调的阶段来进行外部信息的融入的,如下图所示:
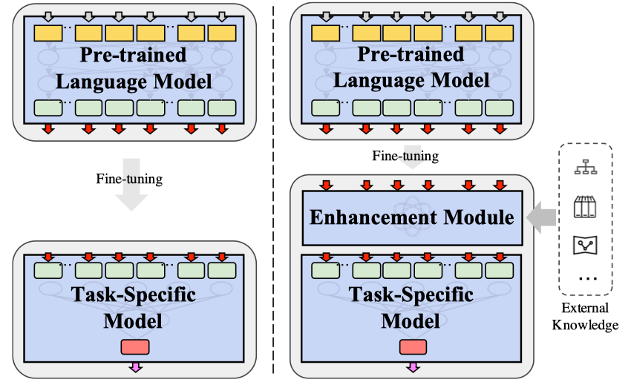
这样的方式有个好处,可以避免重新预训练所带来的高昂代价,并且实验证明了这样的方法可以在多个中文自然语言处理任务上对原生的BERT等模型带来有效的提升。
MWA是利用一种非标准形式的分段式attention方法,将中文的分词切割信息应用到字符表示产生的attention权重上,对同一个词中的不同字进行mix-pooling聚合,从而让字的attention权重强行在词的级别上进行对齐。这样的设计有效地融入了分词的分段式的结构信息,但也带来了一些新的问题:由于需要逐词、逐样本地计算attention的聚合,会导致attention模型中原本可以向量化、并行化的标准矩阵运算变成需要各自运算、无法并行的高负载运算,并且这样的算子无法利用cudnn原语的加速,也无法享受当今非常重要的深度学习计算加速硬件(如GPU、TPU等)带来的速度提升。
此外,MWA使用了简单的mix-pooling来汇聚字级别的attention权重到词级别,这样简单的pooling方式会导致一部分分词结构上的信息损失,没有很好地反应字到词、字到字的层级化交互形式,而是以平均值的形式将字词进行了统一。
最后,MWA提出可以使用多个分词器,融合多个分词器带来的分词信息,以进一步提升模型的效果,但MWA中使用了非常原始的线性加权的形式,对不同分词器产生的MWA字符表示进行加权求和,这样的形式不仅没有体现出不同分词器所带来的分词纠错的效果,还会产生训练参数的膨胀。因此,作者希望重新思考MWA带来的效果提升与随之产生的副作用,试图以一种更加自然的方式来建模相同的中文语言学结构信息,同时避免上述提到的问题。
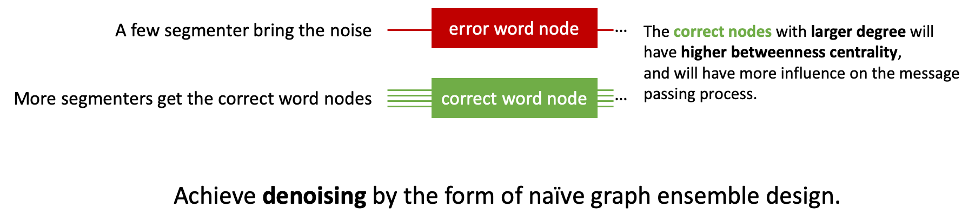
受到MWA和多图集成(Multi Graph Ensemble)相关工作的启发,作者以“去噪”这一动机为核心,构建了中文语言学结构异质图(HLG)。在MWA中,作者提出了使用更多的分词器,会得到更好的效果;然而,无上限地加更多的分词信息难道能持续地带来性能提升吗?未必。当引入更多分词器的同时,也会引入更多的分词错误信息,即噪音。这些噪音信息会影响模型的训练效果,带来一定的副作用;如何让正确的分词结构在模型中起到更大的影响力,让错误的分词信息在模型中产生的影响被尽可能忽略,是构建HLG时所考虑的重点。
从模型集成(Model
Ensemble)考虑,各个已经训练好的分词器是良好的学习者(well-learner),它们各自产生的结果可以假设为大部分正确而小部分错误。因此,可以以模型集成的观点将它们产生的结果合在一起,体现出“少数服从多数”的投票效果,即如果有更多的分词器认为某个词A应当分出来,那么就应当认为这是更加可信的结论,而少数几个分出不同结果的分词器,则在词A的切分上被认为是不那么可信的。在图(Graph)的性质上看,就是让这些正确的分词节点的桥接中心性(betweenness
centrality)更大,这些节点在图的信息传递过程中起到的效果就越大。如下图所示:
以此为动机,作者设计了以字、词、句三个层次的节点构成的HLG,整体的结构如下图所示:
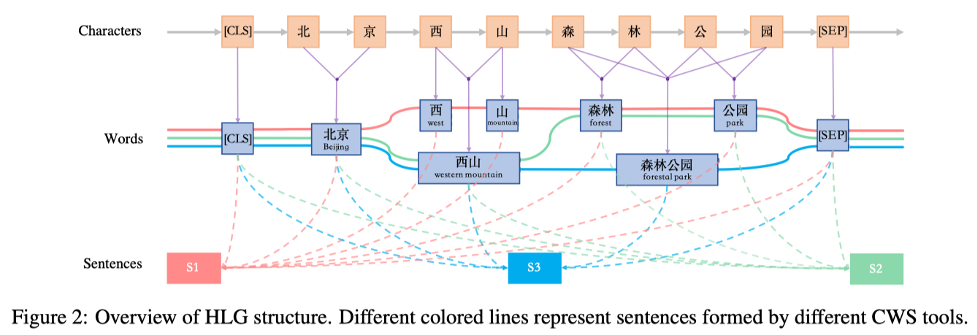
在HLG中,不同分词器产生的不同的词会产生不同的词节点,而在相同位置分出的相同的词会作为同一个词节点;由于一句话以不同的方式切割会自然地产生不同的语义,因此每个分词器分割的句子都作为一个单独的节点存在,分词器分出的词会与对应的句子节点相连。
HLG的构图方法在实质上就满足了前面提到的去噪的动机。以上图中“西山”节点,和“西”、“山”节点为例,前者(西山)有两个分词器支撑这个分词结果,而后者(西、山)只有一个分词器支撑,前者产生的节点在图中的度数会比后者更高。
得到HLG之后,需要使用图神经网络对这个图进行建模,而图神经网络通常处理的是只有一种节点类型的同构图(Homogeneous
Graph),而HLG是有着多种节点类型、多种连边类型的异质图(Heterogeneous
Graph)。因此,论文中使用了一种“多步”的信息传播方式,使用多个GCN层来控制不同层级的信息传播,从而实现了对HLG的建模。如下图所示:
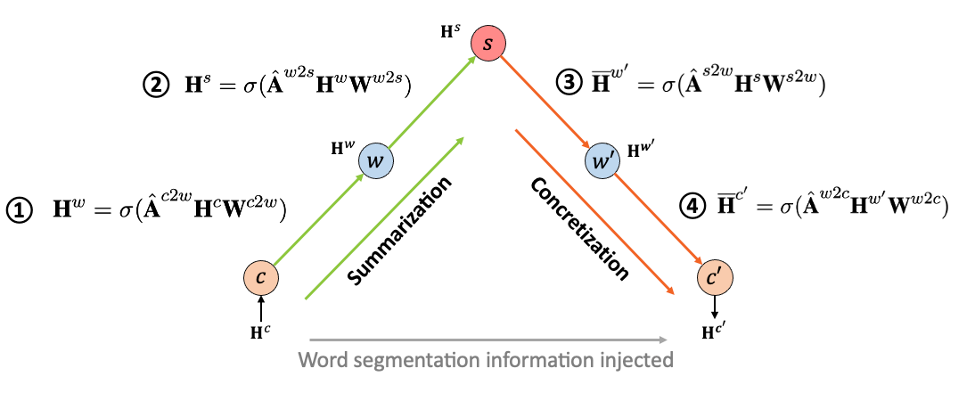
整个信息传播过程的输入\(H^c\)是预训练语言模型的字符级别表示,输出\(H’^c\)是融入了分词信息后的字符级别表示;c、w、s节点分别代表字节点、词节点和句子节点;箭头构成的传播链与数字对应的公式对应,是多个GCN层分别对单跳中的节点信息进行建模,A为邻接矩阵(adjacency matrix)。这个传播过程可以分为两部分:(1)归纳化(Summarization),从字节点到词节点再到句子节点,HLG通过降低的节点数量将字符级别表示按照分词器构造出的路径汇总、归纳到句子级别上;(2)具体化(Concretization),从句节点到词节点再到子节点,HLG将归纳到句级别的表示再逐层根据分词器产生的路径具象化到词、字上。这两部分在上图中以不同的颜色标识。通过这两个步骤后,分词结构信息(以邻接矩阵的形式表达)被纳入到字符级别表示的输出中。
但是,由于句节点的数量(与使用的分词器数量相同)会远远小于词节点和字节点的数量,因此将分词结构表示到句子节点后很难再具象化回字级别,阻碍了信息在图中的传播。这一点在模型训练中会体现为难以训练、效果降低等情况,因此,为了降低这种负面影响,作者引入了ResNet[4]的Skip-Connection,以残差连接的形式在归纳化和具象化过程中相同层级的节点间建立了通路,如下图所示:
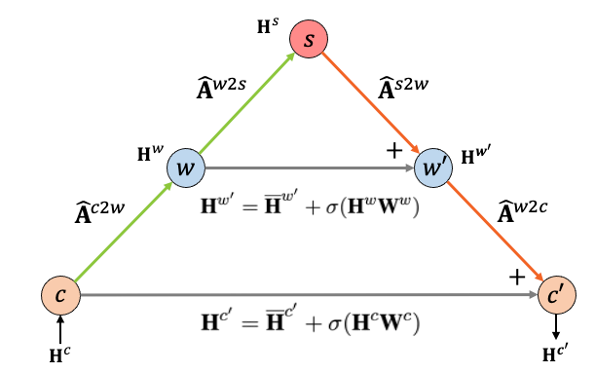
由此,MSIP可以对HLG进行建模,从而在具体任务的微调过程中对模型参数进行学习训练。
与MWA相比,HLG的主要区别是,增加了句子节点,并将信息聚合与分发的方式进行了调整,从对attention权重的分段pooling改成了对层级图的GCN。而它们的输入、输出,以及融入的外部知识实际上都是一致的。下图说明了MWA和HLG在文本表示信息和分词结构信息聚合-分发过程中的异同:

论文对提出的模型在多个预训练语言下游任务基准数据集上进行了实验验证,结果如下:
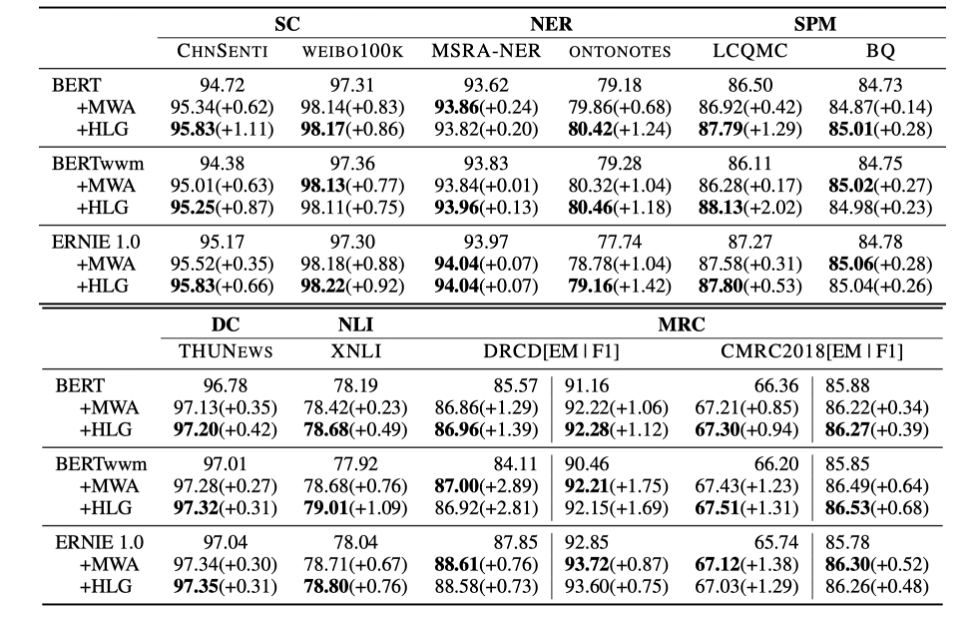
与原生的预训练语言模型相比,HLG带来了稳定的提升;与MWA相比,HLG的实验效果也并不逊色。而在训练和推理效率方面,HLG可以说是一骑绝尘,甩开MWA一大截:
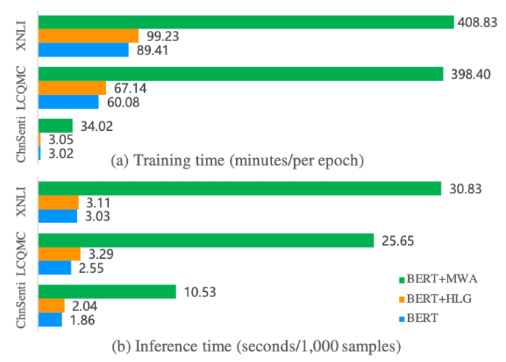
速度上基本上有着7倍以上的提升。对前面提到的“去噪”的动机,作者也通过引入更多分词器的方式进行了验证:
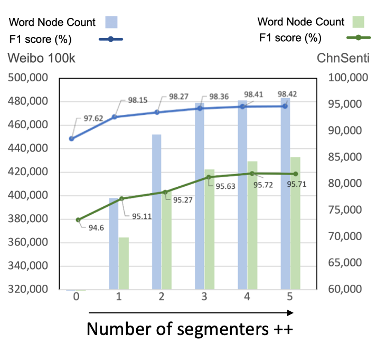
从1个分词器向上提升分词器数量的同时,会得到更多的词节点(新的分词器分出了不同的词),而效果也有微幅提升;引入更多的分词器时,增加的新的词节点的数量开始逐渐下降(由于加入的新的分词器分出的词与已有分词器的大体相同),而带来的性能相对提升也在逐渐降低;引入5个或超过5个分词器,带来的性能提升基本上没有了,甚至可能会出现效果衰退的情况,可能是由于带来了过多的噪声。作者在权衡使用多分词器引入的噪声、提升的效果和增加的预处理开销后,最终还是只使用了3个分词器。
这篇论文的贡献点可以归结为几块: 1. 对于MWA提出的在预训练模型微调过程中引入新的模块,从而引入外部知识的做法,作者将其总结为了一种强化模块(enhancement module)的适配器(adapter),这样的方法可能在其它领域也能发挥作用; 2. 作者提出了HLG来表示中文的分词的结构,并且可以在引入多个分词器的情况下体现出一定的去噪效果。同时,作者以MSIP的方法,成功用图神经网络对HLG这种异质图进行了建模; 3. 实验结果表明,这篇论文提出的HLG的方法与MWA带来的模型性能提升不分伯仲,但相比于MWA,HLG节省了至少一半的模型参数量,并且得益于标准的运算模式,HLG的训练、推理速度比MWA快了约7倍以上。
这篇论文的代码已经开源,可以在 GitHub 上找到。
使用 Flask 做应用时,用了 Apscheduler
作为后台任务及定时任务执行器,使用方式类似于 1
2
3
4
5
6
7
8
9from flask import Flask
from apscheduler.schedulers.background import BackgroundScheduler
app = Flask(__name__)
scheduler = BackgroundScheduler()
if __name__ == '__main__':
scheduler.run()
app.run(debug=True)
在调试时,直接用 python3 app.py
运行,一切正常。但是在使用 gunicorn 切换到生产环境时,使用
gunicorn -w 1 -b 0.0.0.0:5000 app:app 时,却出现了
apscheduler 的后台任务不运行的情况;
直接运行 python3 app.py 自然是以顺序执行,并且程序的
__name__ 是 __main__,自然
scheduler.run() 和 app.run()
会正常执行;但经过查阅资料和接口文档得知,gunicorn 是将 app:app 即
app.py 中的 app 对象(Flask 实例)作为入口的,而此时程序的
__name__ 是 app,因此
scheduler.run() 直接就不执行了。
所以,对于单进程(多线程)的任务,直接将 scheduler.run()
放在 __name__ 判断条件外,就能正常执行了:
1
2
3
4
5
6
7
8
9from flask import Flask
from apscheduler.schedulers.background import BackgroundScheduler
app = Flask(__name__)
scheduler = BackgroundScheduler()
scheduler.run()
if __name__ == '__main__':
app.run(debug=True)
当然 app.run()
还是要放在判断中的,只在调试模式下运行。
近年来,预训练语言模型在NLP领域展现出了强大的能力而被广泛采用,成为了解决NLP问题的“银弹”。借助大规模数据集、以Transformer为代表的深度神经网络模型、以及设计好的自监督预训练(pre-train)任务,预训练语言模型展现出了强大的泛化能力,经过微调(fine-tune)后在各个下游任务中得到了优秀的成果,其强大性能让人对其学习到的内容产生了兴趣:预训练语言模型是否真的在预训练过程中学习到了“知识”呢?
最近也有工作提出了prompt范式,通过构建的prompt语句,将特定的下游任务转换为预训练语言模型的预训练任务(如Mask Language Model)从而得到结果,这种形式有点类似于从知识库中使用一定的查询语句找出对应的答案。因此,有研究者开始探索是否能将预训练语言模型作为“知识库”使用。本文针对自然语言处理中的预训练语言模型如何通过预训练建模“知识”、推导知识,以及预训练语言模型是否能作为知识库这三方面进行了简单的论文导读。
此论文《Open Domain Question Answering Using Early Fusion of Knowledge Bases and Text》发表于 EMNLP 2018。
对于开放域问答问题,作者试图将与问题有关的 Wikipedia 和 Freebase 的知识结合起来构成一个融合子图,然后把开放域问答问题转换为在这个融合子图上的节点分类问题,是一篇典型的早期融合的工作。如下图的左右两部分所示,该文章要点有两处:(1)如何对知识库和文本进行联合构图;(2)如何在图上执行节点分类获得问题的答案。
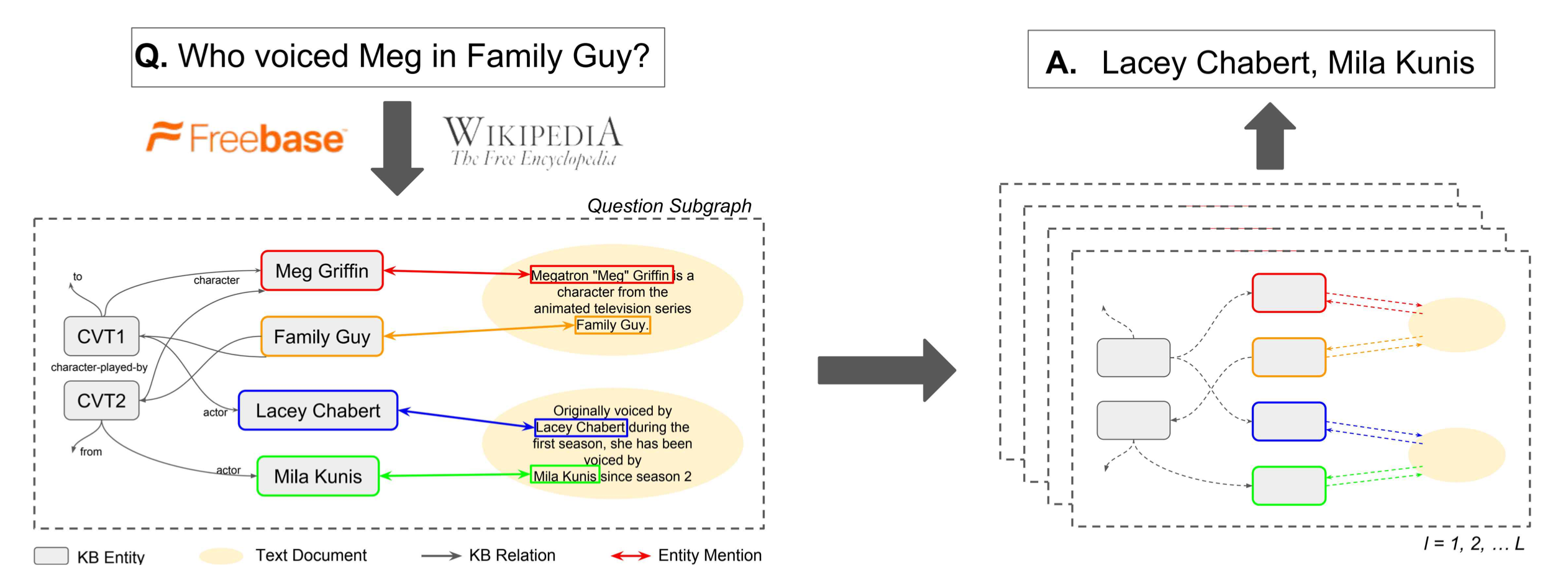
将整个Wikipedia与Freebase进行联合构图是不现实的,因此作者先分别在知识库找出与问题相关的部分,然后通过不断在文本库中检索文本相关文本,加入融合子图中。
(1)从知识库构建问题相关子图:首先通过实体链指从问题\(q\)中获取一系列种子实体\(S_q\),然后以这些种子实体为起点,执行Personal PageRank(PPR)算法,根据PPR得到的权重找出与种子实体相连的Top-E候选实体\(v_{1}, \ldots, v_{E}\),将种子实体、候选实体和他们间的连边合起来,构成子图\(\mathcal{G}_q = \left(\mathcal{V}_{q}, \mathcal{E}_{q}, \mathcal{R}\right)\),其中\(\mathcal{V}\)为节点,\(\mathcal{E}\)为连边,\(\mathcal{R}\)为边的类型(即关系类型)。
(2)文本信息节点:首先通过DrQA的带权词袋模型对文本库进行句子级别的检索,得到Top5与问题相关的文档,然后根据问题\(q\)与文档中的句子进行检索排序,找出最相关的Top-D个候选句子\(d_{1}, \ldots d_{D}\)。将这Top-D个句子依次加入问题相关子图\(\mathcal{G}_q\)中: \[ \mathcal{V}_{q}=\left\{v_{1}, \ldots, v_{E}\right\} \cup\left\{d_{1}, \ldots, d_{D}\right\} \] 对于节点的连边,以如下的形式进行连接: \[ \mathcal{E}_{q}=\left\{(s, o, r) \in \mathcal{E}: s, o \in \mathcal{V}_{q}, r \in \mathcal{R}\right\} \cup\left\{\left(v, d_{p}, r_{L}\right):\left(v, d_{p}\right) \in \mathcal{L}_{d}, d \in \mathcal{V}_{q}\right\} \]
其中\(r_L\)表示从文档句子到实体的连边关系。即,将句子和图\(\mathcal{G}_q\)中已有的实体添加连边。由此,得到了包含知识库信息和文本信息的融合子图\(\left(\mathcal{V}_{q}, \mathcal{E}_{q}, \mathcal{R}^{+}\right)\),\(\mathcal{R}^{+}=\mathcal{R} \cup\left\{r_{L}\right\}\)。
在上一步中,已经获得了包含知识库节点、文档节点、文档到实体连边的与问题\(q\)相关的异构融合子图\(\mathcal{G}_q\)。此工作先采用图表示学习的方法得到各个节点的表示,然后对各个节点是否属于答案进行二分类训练。该方法命名为GRAFT-Net,分为两步:
(1)初始化节点表示:对于知识库中的实体节点,赋予定长表示向量:\(h_{v}^{(0)}=x_{v} \in \mathbb{R}^{n}\),其中\(x_v\)可以是随机向量也可以是通过TransE等方式预训练得到表示向量。对于文本的文档节点,如果文档是由单词\(w_{1}, \ldots, w_{|d|}\)构成的,则使用LSTM对词嵌入进行编码\(H_{d}^{(0)}=\operatorname{LSTM}\left(w_{1}, w_{2}, \ldots\right)\)。
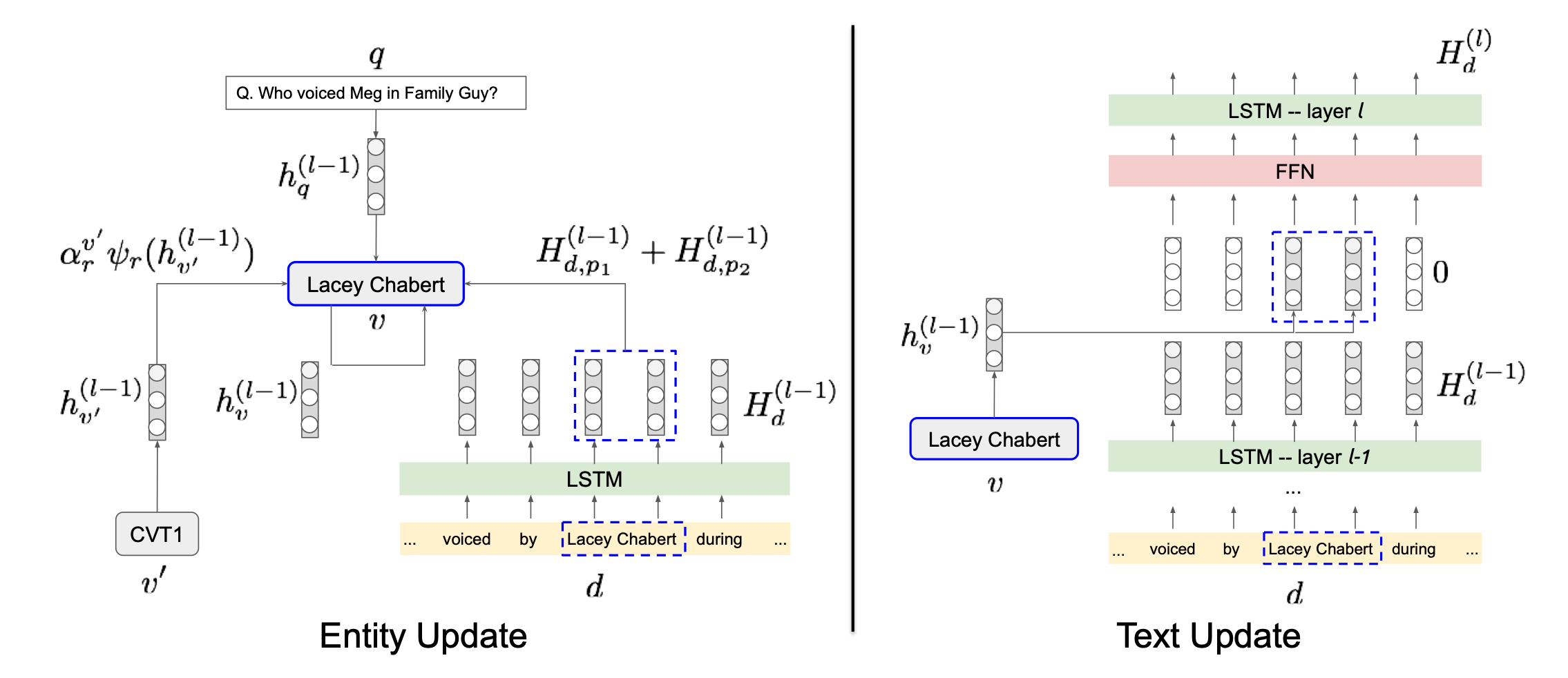
(2)异构融合子图的更新:由于前一步得到的图是异构的,需要根据问题\(q\)分别对实体节点与文档节点进行更新,如上图所示。对于实体节点\(v\),每一层GRAFT-Net执行如下更新: \[ h_{v}^{(l)}=\mathrm{FFN}\left(\left[\begin{array}{c} h_{v}^{(l-1)} \\ h_{q}^{(l-1)} \\ \sum_{r} \sum_{v^{\prime} \in N_{r}(v)} \alpha_{r}^{v^{\prime}} \psi_{r}\left(h_{v^{\prime}}^{(l-1)}\right) \\ \sum_{(d, p) \in M(v)} H_{d, p}^{(l-1)} \end{array}\right]\right) \] 其中\(h_{v}^{(l-1)}\)是上一层该节点的表示,\(h_{q}^{(l-1)}\)是上一层的问题表示,\(\sum_{r} \sum_{v^{\prime} \in N_{r}(v)} \alpha_{r}^{v^{\prime}} \psi_{r}\left(h_{v^{\prime}}^{(l-1)}\right)\)中的\(N_{r}(v)\)是节点\(v\)的邻居实体节点,\(\psi_{r}\left(h_{v^{\prime}}^{(l-1)}\right)\)是根据PageRank的权重控制连边上的权重传递(propagation),\(\alpha_{r}^{v^{\prime}}\)是在关系\(r\)上执行注意力机制加权,以权衡问题节点对实体节点的影响;\(\sum_{(d, p) \in M(v)} H_{d, p}^{(l-1)}\)中的\(M(v)\)是与节点\(v\)相邻的文档节点,\(H_{d, p}^{(l-1)}\)是实体在文本中的表示。 而文档节点的表示,是由一系列单词的表示再通过LSTM进行编码得到的,因此文档节点表示的更新本质上是文档中单词表示的更新。假如文档\(d\)中位置\(p\)上的单词与实体节点相连,将这些实体节点记为\(L(d, p)\),该单词的表示更新如下所示: \[ \tilde{H}_{d, p}^{(l)}=\operatorname{FFN}\left(H_{d, p}^{(l-1)}, \sum_{v \in L(d, p)} h_{v}^{(l-1)}\right) \] 实质上就是对邻接实体节点进行了聚合。最后,文档节点也会更新:\(H_{d}^{(l)}=\operatorname{LSTM}\left(\tilde{H}_{d}^{(l)}\right)\)。
在问题节点的引导下,GRAFT-Net会以类似PageRank的形式,将问题节点的表示向整个异构融合子图中传播,最终得到融合了问题表示、实体表示、文本表示的异构融合子图中每个节点的表示\(h_{v}^{(L)} \in \mathbb{R}^{n}\)。只需要对它进行二分类训练: \[ \sigma\left(w^{T} h_{v}^{(L)}+b\right) \] 就能分出融合子图中与问题相关的节点了,即得到了问题的答案。
《Question Answering over Freebase with Multi-Column Convolutional Neural Networks》发表于 ACL 2015,这篇论文是《Question Answering with Subgraph Embeddings》的后续工作。
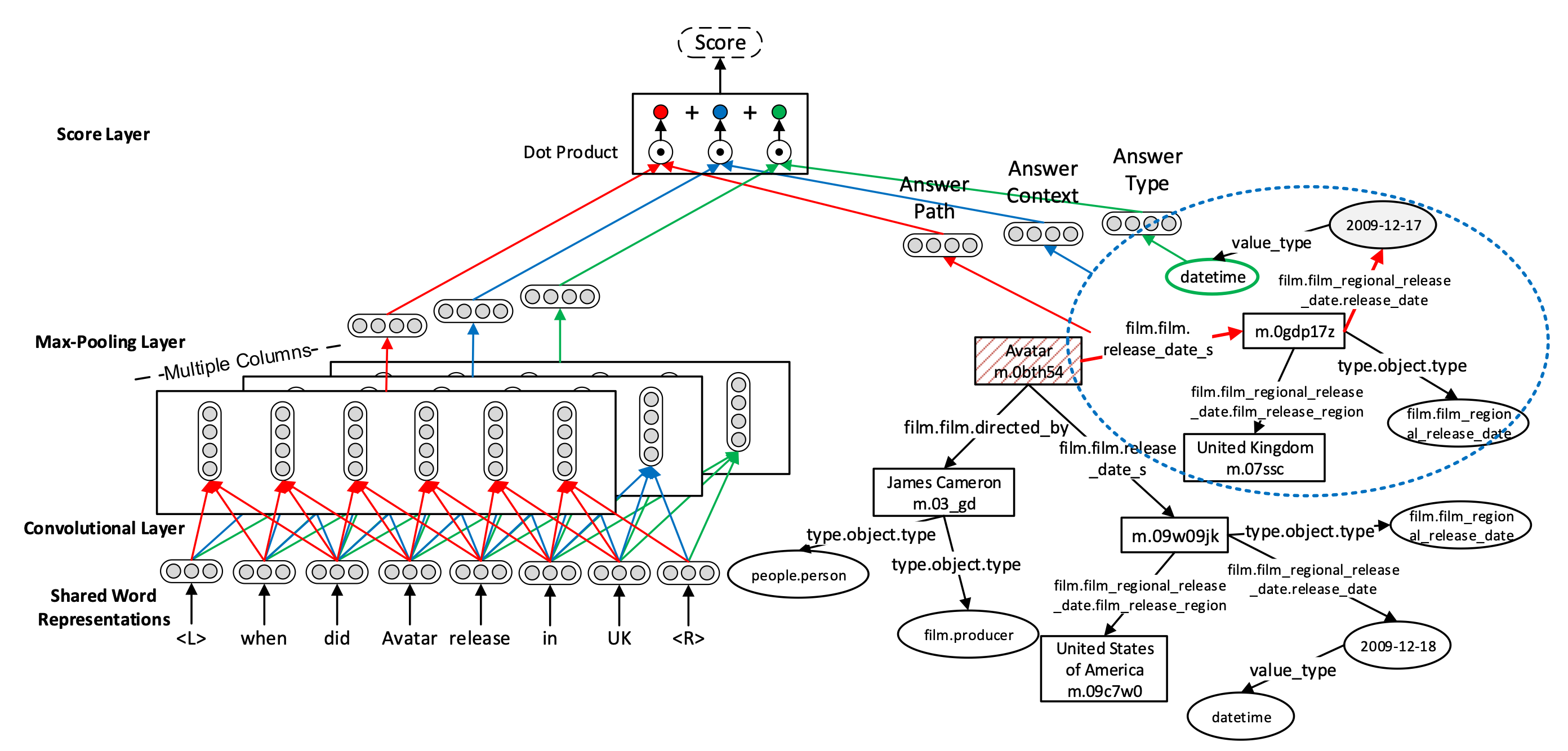
上图展示了该工作的主要模型,可以看到与基于子图嵌入的知识库问答一文类似,也是主要分成了两个部分:问题的文本表示,与答案候选集的子图表示。
对于问题的文本,此论文使用了与TextCNN类似的方式,使用卷积神经网络对问题的词嵌入进行滑动卷积与池化,从而得到问题的文本表示: \[ \mathbf{x}_{j}^{(i)}=\mathbf{h}\left(\mathbf{W}^{(i)}\left[\mathbf{w}_{j-s}^{\top} \ldots \mathbf{w}_{j}^{\top} \ldots \mathbf{w}_{j+s}^{\top}\right]^{\top}+\mathbf{b}^{(i)}\right) \\ \label{chap9:equ:mccnn} \mathbf{f}_{i}(q)=\max _{j=1, \ldots, n}\left\{\mathbf{x}_{j}^{(i)}\right\} \]
其中,\(\mathbf{W}^{(i)}\)是用于获得不同问题表示\(\mathbf{f}_{i}(q)\)的不同的可训练参数矩阵,公式\(\ref{chap9:equ:mccnn}\)表示的是使用滑动窗口进行卷积的具体过程,在此不再赘述。
对于答案候选集,作者设定了三种特征:
(1)答案路径:对于从问题中的实体节点到答案节点的路径的表示,此论文采用了和《基于子图嵌入的知识库问答》中路径表示一样的方法: \[ \mathbf{g}_{1}(a)=\frac{1}{\left\|\mathbf{u}_{p}(a)\right\|_{1}} \mathbf{W}_{p} \mathbf{u}_{p}(a) \]
其中,\(\mathbf{u}_{p}(a)\) 为路径上每一个关系的稀疏向量表示,\(\mathbf{W}_{p}\) 为可训练参数,由于答案路径长度不一,因此作者使用\(\frac{1}{\left\|\mathbf{u}_{p}(a)\right\|_{1}}\)进行了归一化。
(2)答案上下文(Context):该文将与答案相邻一跳的实体和关系称为答案的上下文,使用同样的方法进行嵌入表示: \[ \mathbf{g}_{2}(a)=\frac{1}{\left\|\mathbf{u}_{c}(a)\right\|_{1}} \mathbf{W}_{c} \mathbf{u}_{c}(a) \]
其中,\(\mathbf{u}_{c}(a)\)为答案周围一跳子图的实体和关系的稀疏向量表示,其余参数与答案路径中的相仿。
(3)答案类型:作者认为,类型信息对于知识库问答十分重要,可以根据问题直接限定到答案的类型。例如当问题中有“Where”的时候,答案也应有很大的可能是与“location”相关的类型。因此,作者对答案的类型进行了与前文类似的表示: \[ \mathbf{g}_{3}(a)=\frac{1}{\left\|\mathbf{u}_{t}(a)\right\|_{1}} \mathbf{W}_{t} \mathbf{u}_{t}(a) \]
如果答案是属性值,作者会将答案的类型定义为它的数值类型(如浮点数、字符串、日期等)。
获得上述三种答案候选的特征后,作者将这些特征与问题的表示进行联合打分计算相似度: \[ S(q, a)=\underbrace{\mathbf{f}_{1}(q)^{\top} \mathbf{g}_{1}(a)}_{\text {answer path }}+\underbrace{\mathbf{f}_{2}(q)^{\top} \mathbf{g}_{2}(a)}_{\text {answer context }}+\underbrace{\mathbf{f}_{3}(q)^{\top} \mathbf{g}_{3}(a)}_{\text {answer type }} \]
然后同样使用hinge loss损失函数进行训练: \[ \sum_{q} \frac{1}{\left|A_{q}\right|} \sum_{a \in A_{q}} \sum_{a^{\prime} \in R_{q}} l\left(q, a, a^{\prime}\right) \\ l\left(q, a, a^{\prime}\right)=\left(m-S(q, a)+S\left(q, a^{\prime}\right)\right)_{+} \]
其中\(a^{\prime}\)为答案\(q\)的负样本(即错误答案)。
实验证明,这篇论文的方法比《Question Answering with Subgraph Embeddings》的方法效果更好。作者构建了消融实验,用数据证明了上述的各个特征和步骤都对最终的结果有着正面的影响。
《Question Answering with Subgraph Embeddings》发表于 2014 年的 EMNLP,提出了一种基于对问题嵌入与候选子图嵌入进行打分的排序学习的方法,是基于信息检索的知识库问答中比较有代表性的工作。
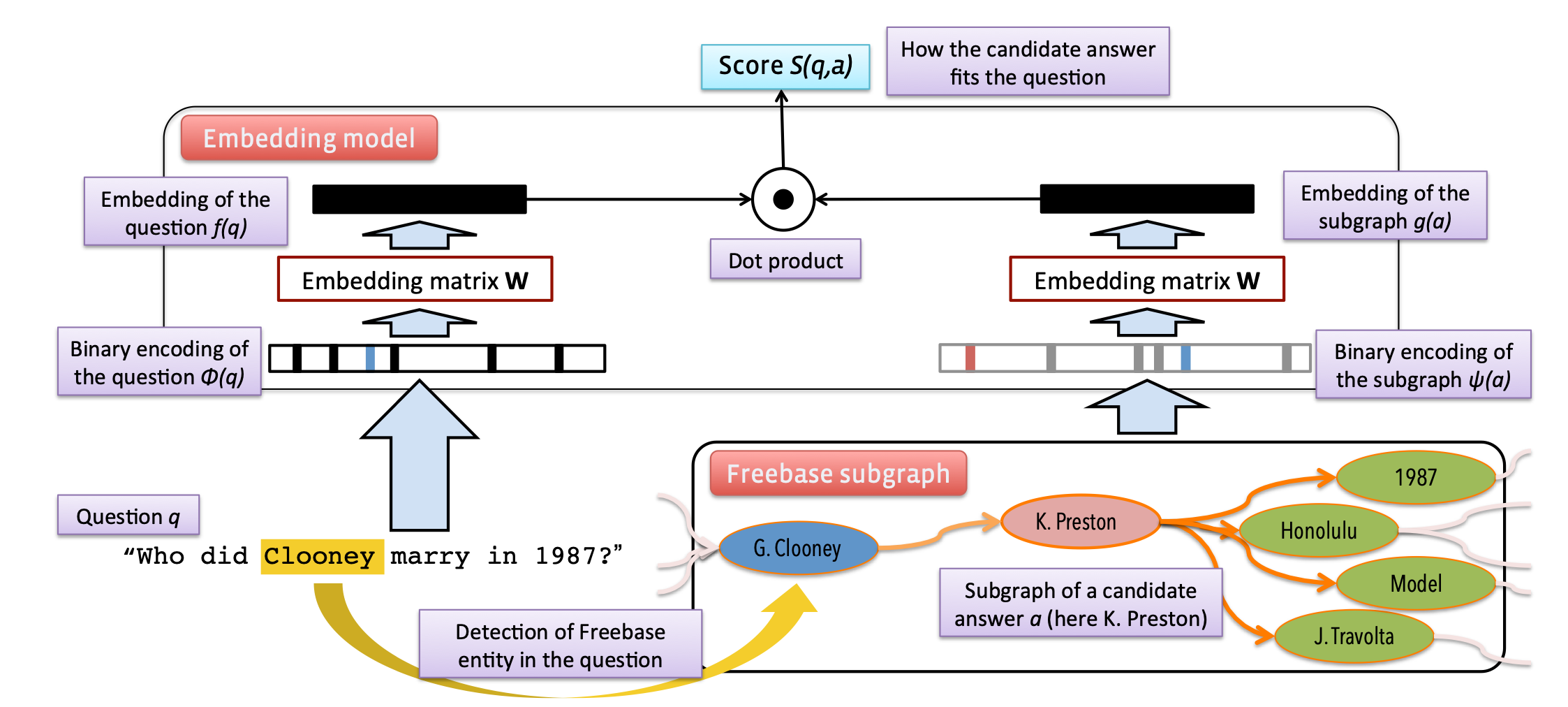
上图展示了该工作的主要方法。如图所示,此方法主要包含问题嵌入与子图嵌入两个分支。
为了获得问题的嵌入,该文使用了同一种稀疏统计表示方式,即统计问题中每个单词的词频,从而得到与整个词表大小相同的稀疏统计向量表示:\(\phi(q) \in \mathbb{N}^N\),其中\(\phi(q)\)为问题的稀疏统计向量,\(N\)为整个词表(包括单词\(N_W\)、知识库中的实体和关系\(N_S\))的大小。 接着,通过一个可训练词嵌入参数矩阵\(\textbf{W}\),获取问题的稀疏统计向量的低维稠密的文本嵌入表示: \[ f(q)=\mathbf{W} \phi(q) \]
作者对答案的嵌入表示\(g(a)\)提出了三种方案:
(1)实体嵌入:与问题嵌入的方式相同,直接通过实体 one-hot 在共享的词嵌入参数矩阵中获取对应的嵌入: \[ g(a)=\mathbf{W} \psi(a), \] 其中\(\psi(a)\)为与\(\phi(q)\)类似的稀疏统计向量,会将答案以\(N_S\)维的稀疏向量表示,\(g(a)\)为获得的实体嵌入(即答案嵌入)。如果一个问题存在多个答案,则直接对多个答案的嵌入表示求平均。
(2)路径嵌入:该工作会考虑最多两跳的答案路径。例如对一个两跳的答案路径:(barack obama, people.person.place of birth, location. location.containedby, hawaii)中的头实体、尾实体和路径上的所有谓词都使用\(\psi(a)\)进行嵌入。
(3)子图嵌入:对一个答案,在一跳或两跳的范围内构建子图,对这个子图中包含的实体和关系同样使用\(\psi(a)\)进行嵌入。但为了区分答案路径与子图中实体和关系,作者对\(N_S\)设定了两倍的大小,子图和路径的嵌入分别使用不同的部分。
通过上述的方法分别获取问题的嵌入\(f(q)\)与候选答案的嵌入\(g(a)\)后,可以对它们进行相似性评分: \[ S(q, a)=f(q)^{T} g(a), \] 然后使用hinge loss损失函数进行训练: \[ \sum_{i=1}^{|\mathcal{D}|} \sum_{\bar{a} \in \overline{\mathcal{A}}\left(a_{i}\right)} \max \left\{0, m-S\left(q_{i}, a_{i}\right)+S\left(q_{i}, \bar{a}\right)\right\} \] 其中\(D\)为训练集,\(q,a\)分别为问题和答案,\(m\)为 margin,\(\bar{a}\)为\(q_i\)的负样本。最小化该损失函数可以达到让问题与正确答案的打分尽可能大,让问题与错误打分的打分尽可能小的目的。
实验证明,这篇论文提出的方法在 WebQuestions 数据集上得到了优秀的结果。对比实验也发现,使用子图嵌入来作为答案的嵌入比其它两种方式效果更好。
在使用 NNI
自动跑实验,过了几个小时去看了一眼状态,结果发现有任务一直处于
WAITING 状态(如图所示),而实际上服务器的 GPU
并非处于全部被占用的状态。

经过查阅 issue 与查看源码,发现 nni 判定 WAITING
状态的任务在何时可以执行并将状态转变为 RUNNING 的条件是文件
/tmp/<user_name>/nni/script/gpu_metrics 中
gpuInfos 字段下各 GPU 的状态
activeProcessNum。由于服务器上有 GPU 实时监控软件在不断调用
nvidia-smi 程序,导致 nni 的检查 GPU 状态的程序一直卡在
nvidia-smi 处。
而 nni 中专门有个脚本可以用来检测 GPU 使用情况并更新
gpu_metrics
文件:/<python_path>/site-packages/nni/tools/gpu_tool/gpu_metrics_collector.py。查看代码可以看到:
1 | def main(argv): |
因此,将环境变量 METRIC_OUTPUT_DIR 设定在
gpu_metrics 所在的目录,即可自动生成最新的 GPU
状态。在我这儿卡住的服务器上 kill 掉无响应的 nvidia-smi
程序,执行
METRIC_OUTPUT_DIR=/tmp/<user_name>/nni/script/ python3 -m nni.tools.gpu_tool.gpu_metrics_collector,成功地让一直卡在
WAITING 状态的程序继续运行,状态转为
RUNNING。
为了后续不被卡住,特意用了 crontab 定期执行一次杀掉
nvidia-smi 和执行 gpu_metrics_collector
的操作,一劳永逸。