Enhancing Pre-trained Chinese Character Representation with
Word-aligned Attention
一文是我和组内同学、师兄的合作工作,作为短文录用于 ACL 2020。
说起来很奇妙,这个工作最开始是为了做 Aspect-extraction
相关工作而开始的,效果很一般。但是在调参的时候发现单纯作为序列标注任务的一个额外的特征输入,居然得到了一丁点提升。也就是这一点点提升,我决定把它应用在预训练语言模型中做一做实验。在经过大量的试错、调整和调参后,最终得到了这么一种新奇的方法,可以让预训练语言模型额外获得一些
word-level
的信息,在各个需要词信息的任务中都有那么一点提升。但这个方法相当的实验化且缺乏理论支撑,并且还有一些别的致命问题(如果没有这些问题谁会去投短文...),会在后面一一说明。下文将结合在会上做远程汇报的
slide,简单描述这个工作。
ppt 已经放在这里 了
反正就是想写个笔记给自己看,又不是写论文,就不用玩啥避重就轻之类的套路了,吐槽为主 (反正没人看)。
概述
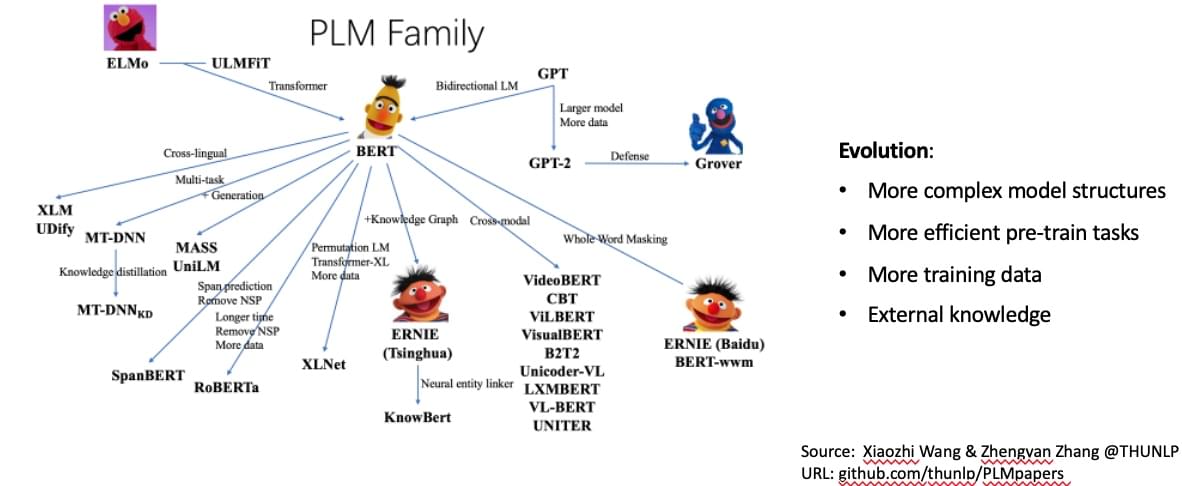
-w591
首先是预训练语言模型在最近有了很大的发展,上面那个图是 thunlp
组同学整理的。现在预训练语言模型发展方向就是在不断改进预训练任务和模型结构,让其能适配更大量的数据的数据,方便刷榜,看看
GPT-3 那 1700
亿个参数就心酸。当然也有许多做压缩模型、蒸馏的工作,这些现在应用起来反而更实用一些。还有一些工作在尝试融入额外信息,比如:清华
nlp 提出的 ERNIE 在 BERT 中融入知识图谱;百度的 ERNIE 1.0
融入实体信息,ERNIE 2.0 花式训练;香侬科技魔幻的 Glyce
融合字形;创新工场的 ZEN 用 n-gram 去融合分词信息。
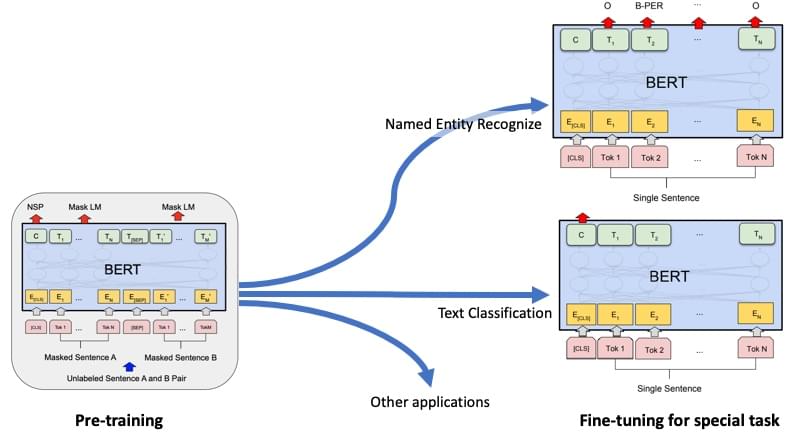
-w399
但是不管怎样边,主流的预训练语言模型都和上图一样,分预训练和微调两个阶段(GPT-3
那种号称不用微调的除外),现在大家的主要工作也是集中在预训练阶段去做的。近些年这块最经典的工作当然非
BERT 莫属了,所以我后面都是在 BERT 上跑实验。
不管啥模型,第一件事都是 tokenizer。对于 BERT 来说,英文的 token 是
word-piece,中文的是字(这也对后面的实验造成了很大的麻烦,因为要对齐)。而且已经有相当多的工作证明了,对于中文在
character-level 建模会比较合适(香侬在 ACL2019 的那篇《Is Word
Segmentation Necessary for Deep Learning of Chinese
Representations》很是经典)。不过在实际应用中,包括很多 Application of
NLP
领域的文章,还有我自己的文章,都发现将词信息融入到文本表示中会对应用有效果。
所以,这篇论文实质上就是在实验看有什么办法去各种拐着弯儿向
character-level 的表示模型融入词信息。
动机
至于动机也很简单。玄一些就是把一些眼动追踪的研究挪过来建模:
[1] Reading spaced and unspaced chinese text: Evidence from eye
movements [2] Parafoveal load of word N+1 modulates preprocessing
effectiveness of word N+2 in Chinese reading [3] Cognitive mechanisms in
reading ancient Chinese poetry: evidence from eye movements
上图就是上面几篇论文的部分结论,总结起来就是人阅读中文的时候对每个词付出的“注意度”类似。
实在一些就是想找一些方法来改变 transformer 的 attention
分布,或者找一种可以折中 soft-attention 与 hard-attention
的方法,在维持原 attention 机制的情况下,用比较 soft 的方法来实现比较
hard 的效果,来方便某些任务(后记中有写)。
总之,我就是根据这些动机进行了实验。
模型
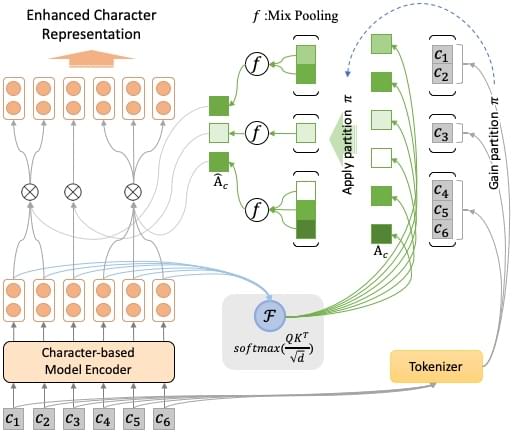
单个分词器下的情况
(在师兄指导下画的图,还挺好看的)
模型很简单,就是在预训练语言模型对下游任务进行微调时,中间插上一层
multi-head attention 的变体。
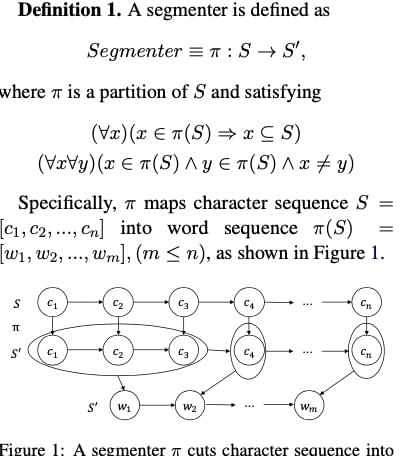
首先,可以使用分词工具将输入的文本进行分词,具体来说就是讲由字构成的序进行划分(parition),我们把这种划分策略称为
\(\pi\) 。
得到划分 \(\pi\)
后,将其应用于正常得到的 attention
权重矩阵上,可以得到按词划分的(word-based)字级别(character-level)的
attention 权重组合。
为了同时考虑:1. 句子中所有词的语义表示;2.
句子中最重要的词的语义表示 这两种情况,我们使用 mix-pooling 来对
mean-pooling 和 max-pooling 进行混合:
\[
MixPooling = \lambda MeanPooling + (1 - \lambda MaxPooling)
\]
其中 \(\lambda\)
为参数(后面做实验观察 \(\lambda\)
发现,还是 MeanPooling 更重要一些)。
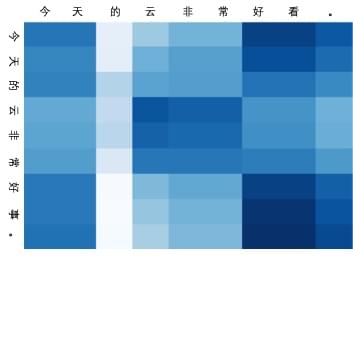
比如上图就是这种 attention
权重矩阵的可视化效果图。这个例子是从情感分类任务模型中拿出来试的,可以看到
attention 权重矩阵被转化为了 character-level to word-level
的形式,而实际上还是 character-level
的模型,保留了字建模的优秀表示,同时也做到了前面动机所说的接近
hard-attention 的效果。
把这样的 attention 权重再拿回 character-level
表示去调整它,就能得到最终的字表示,送往后续的下游任务。
多个分词器下的情况
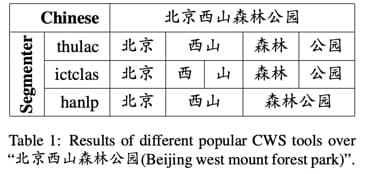
然而,众所周知,分词器经常会出现问题。
上图是论文里的图(为了和平特意找了个都没分错的例子),这几个分词器得到的结果都是对的,但是其粒度不同。
为了减少分词错误,以及用上不同粒度级别的特征,我们找了一种简单的方法,同时用上多个分词工具的分词结果。
\[
\textbf{H'} = \sum_{m=1}^{M} \tanh( {\textbf{H}}^m\textbf{W})
\]
真的很简单,就是几个分词器的结果,分别得到下游表示之后过个线性层结合在一起而已。
实验证明这样是有一定效果的。
实验结果
都在原文里有,没啥槽点,就是做实验耗的时间太多了。
总结
总结一下这个工作的优缺点:
优点:
提出了这么一种有意思的结构
这么一种有意思的结构可以融入一些分词信息,并且对预训练语言模型的下游任务有一些帮助
单纯融入一种分词信息不够,就多加几种分词信息
缺点:
实在缺乏理论支撑
预处理的真的特别特别慢(尤其是要用几种分词器来分词),并且数据预处理无比复杂(因为各个分词器的处理逻辑都不一样,各种特殊符号、数字、英语、日语、繁体啥的全部都要单独处理,尤其是
BERT 会将英语单词 tokenize 成 word-piece,导致 token 对不上,前期实验有
80% 以上的时间都是在搞这些预处理)
在 forward 的时候把 transformer 的时间复杂度 \(O(n^2)\) 变成了 \(O(d
n^2)\) (这还好是常数级),但是要命的是,在这个方法中,每一条训练数据都会有各自不同的分词方式,都只能各自去分段计算
mix-pooling,这导致完全无法应用 cudnn
原语加速,也完全没可能写成矩阵运算来利用 GPU batch 加速,即使直接用 cuda
编程也没法改善。连 forward 都这么慢,backward
更不用说了……这点是致命的,让我的实验时间变得特别特别长,跑个 CMRC
数据集硬生生把 6 个小时的训练时间搞成了 28 个小时,心态都炸了。
总结下来,这个工作其实缺点其实挺明显的,主要集中在预处理和速度极慢这两块上。吐槽:但投稿时
call for short paper 写明白了就是欢迎分享这些不是很完善的 idea
呀,不懂为啥要使劲冲着缺陷打,没这些问题投长文不香吗?
优点主要还是这个结构足够新颖。由于这种东西的预处理实在太
dirty
了,跑起来也慢的令人抓狂 ,我是不打算 follow
这个工作继续做下去了。但是,这种有意思的结构可以用在其它一些 NLP
应用里面,还是可以做一做的。
后记
在郁博文师兄的帮助下第一次写这种实验性质的短文也是挺有意思的。我受到的指导,和我写的文章,一般都是发现问题->分析问题->分析方案->理论支撑方案->实验支撑理论这么个范式;而这篇文章是发现问题->分析问题->哇,有灵感了->实验结果还不错这么个流程,还是蛮奇妙的。但说到底还是缺乏理论支撑,我去年曾尝试用离散数学去建模分词和这个模型的过程(有图为证),还试图用正则化或者标准化等深度学习术语来解释这种模型,但都成功地浪费了大量的时间,在没有理论支撑的情况下,也只能这样了。
-w202
这篇文章的录用还是很侥幸的。在审稿 rebuttal
的时候,审稿人给的分和评价都很一般。正如前文所说,文本的确有很多问题,但几位审稿人最主要的关注点居然都主要集中在空间复杂度和训练参数数量上面,没有抓主要矛盾而是重点抓次要矛盾去了。所以简单回答这些关于参数、空间占用之类的问题值后,有位审稿人改了分,这才被录用。
最后这篇论文出来的时候真是命运多舛,赶上了 2020
年的疫情,不让回实验室,资料、代码啥的全在工位台式机上,又赶上组里的大工程和自己的毕设,只能抽空远程一点一点扒代码,扒到开会都没扒完;后来都有好几位老师同学发邮件索取了,都没办法直接发给人家可以直接跑的模型,只给一个老师发了最主要的那个
attention align
模块,也不知道有没有帮上他的忙;好在后来找了点办法能远程直连了,不然更难受。