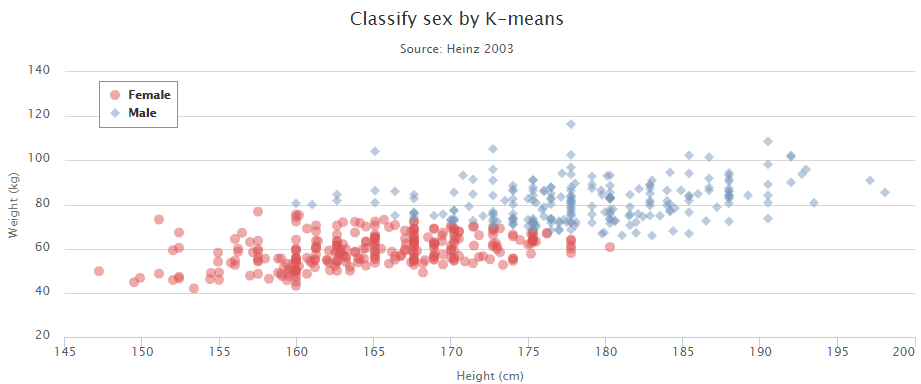
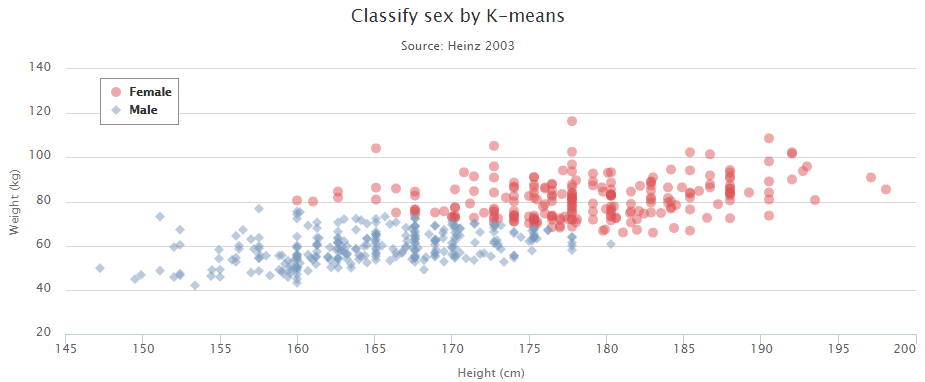
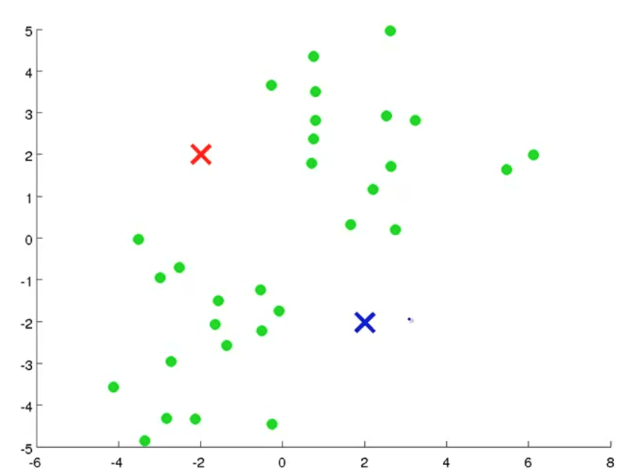
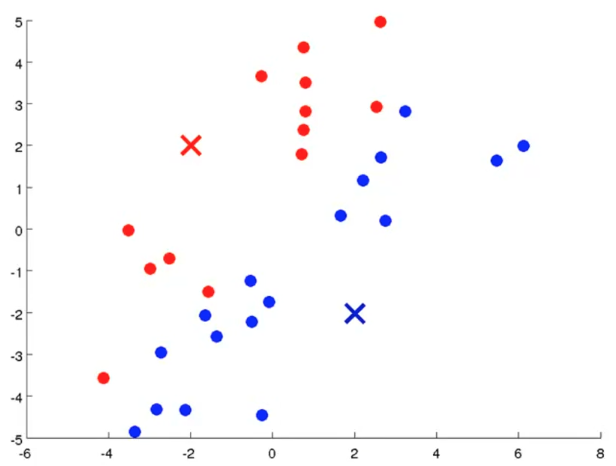
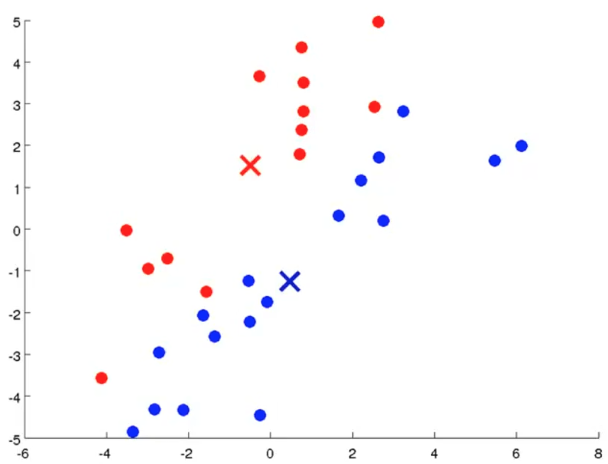
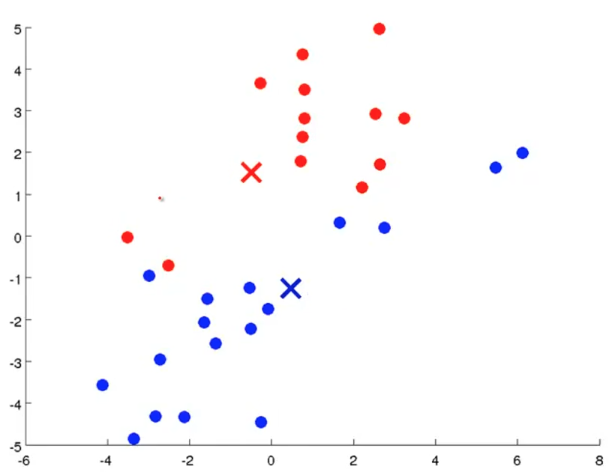
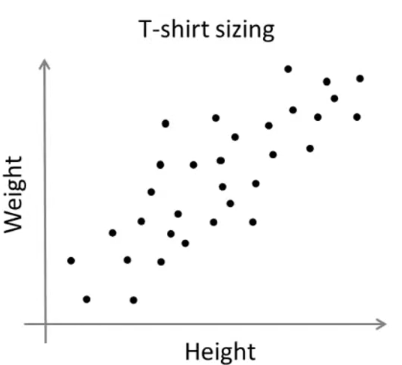
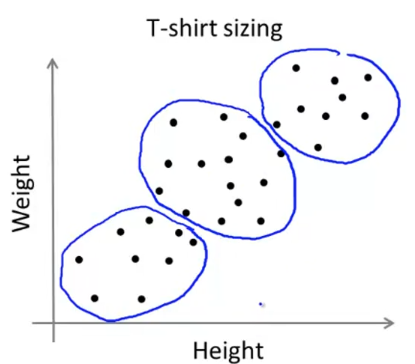
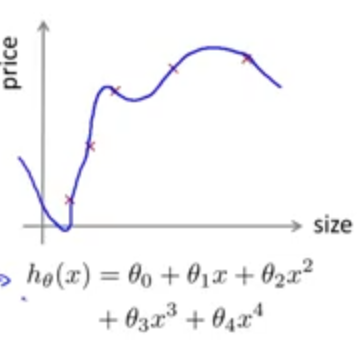
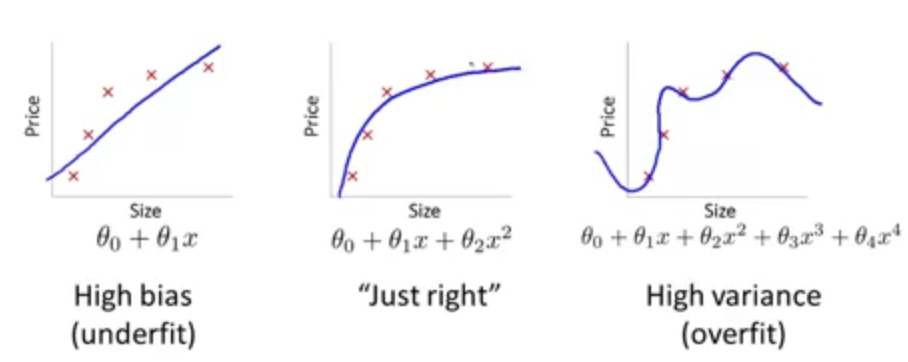
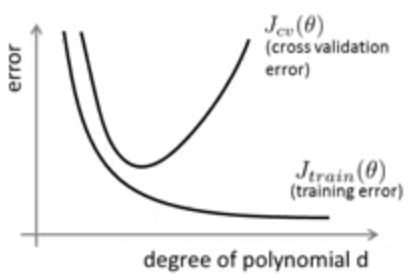
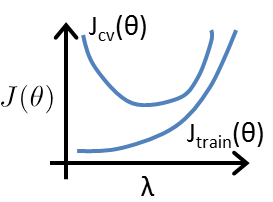
defcount_words(s, n): """Return the n most frequently occuring words in s.""" words = s.split(" ") # TODO: Count the number of occurences of each word in s counters = {} for word in words: if word in counters: counters[word] += 1 else: counters[word] = 1 # TODO: Sort the occurences in descending order (alphabetically in case of ties) top = sorted(counters.iteritems(), key=lambda d:(-d[1],d[0])) ##lambda中"-"为反序,意思是先把单词出现次数从大到小排列, ##然后再以单词的字母从小到大排列 # TODO: Return the top n words as a list of tuples (<word>, <count>) top_n = top[:n]##返回前n个单词 return top_n
deftest_run(): """Test count_words() with some inputs.""" print count_words("cat bat mat cat bat cat", 3) print count_words("betty bought a bit of butter but the butter was bitter", 3)