机器学习学习笔记(十一)调试算法
当发现测试算法时预测的结果有非常大的误差时,有以下几种方法解决问题:
使用更大的训练集
使用更少的特征值
使用更多的特征值
使用更高次幂的特征值
减少正则化参数
增加正则化参数
判断如何选择方法不应该"凭感觉"选择,而应该科学地使用机器学习诊断法进行判断,以更省时间,更有意义地改进算法.
过拟合与欠拟合
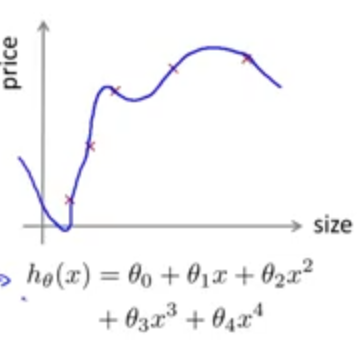
(图为过拟合)
过拟合与欠拟合都将不能很好的匹配新的数据.
方法:将所有数据分为训练集与测试集.比例可以使用7:3.
当训练集的\(J(\theta )\)很小,测试集的\(J(\theta )\)很大时,此时即为过拟合的情况.
\[ J_{test}(\theta )=\frac{1}{2m_{test}}\sum_{i=1}^{m_{test}}(h_{\theta}(x_{test}^{i})-y_{test}^{i})^{2}\]
以上公式即为线性回归测试集误差计算公式;
\[ J_{test}(\theta )=-\frac{1}{m_{test}}\sum_{i=1}^{m_{test}}y_{test}^{i}\log h_{\theta }(x_{test}^{i})+(1-y_{test}^{i})\log h_{\theta }(x_{test}^{i})\]
以上公式为逻辑回归测试误差公式;
可以看到其实误差公式与代价函数的计算是一致的.
通过以上计算公式可以量化测试集测试训练集的训练结果.
确定多项式的次数
已经知道,当多项式的次数过高的时候,会发生过拟合现象.如何根据数据来确定多项式次数d呢?
与之前加上验证集不同的是,将数据集分成三部分:训练集,测试集,交叉验证级.
选择不同的多项式次数分别对验证集进行计算,
\[ 1. h_{\theta }(x)=\theta _{0}+\theta _{1}x\\2. h_{\theta }(x)=\theta _{0}+\theta _{1}x+\theta _{2}x^{2}\\3. h_{\theta }(x)=\theta _{0}+\theta _{1}x+...+\theta _{3}x^{3}\\\vdots \\10. h_{theta }(x)=\theta _{0}+\theta _{1}x+...+\theta _{10}x^{10}\]
得到各自的\(J_{cv}(\theta )\),由此可以选择出最合适的多项式次数.
因此,选择算法使用验证集进行模型选择,使用测试集来评价模型的好坏,这样就能找到合适的模型.
偏差(bias)与方差(variance)
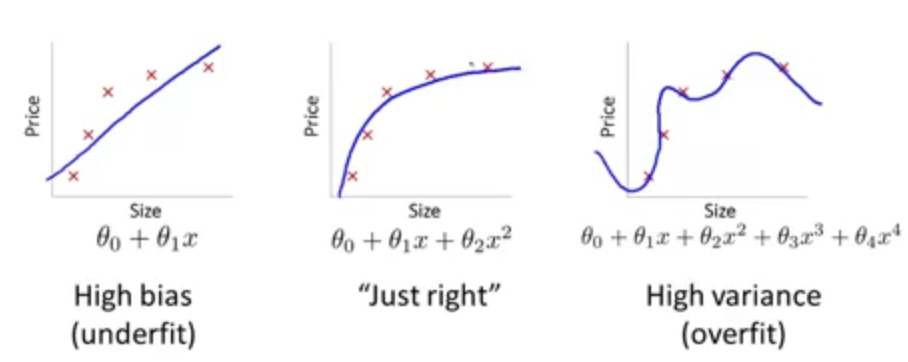
具体来说,欠拟合是高偏差情况,过拟合是高方差情况.
分别对训练集和验证集的误差情况与多项式次数进行画图
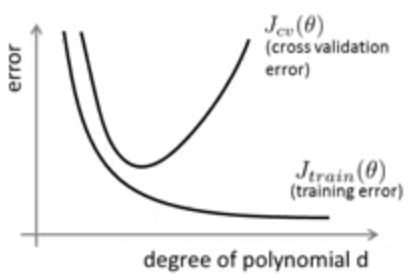
可以看到当项数次数过少时,错误相当的大,此时是高偏差情况;当项数次数过多时,训练集的误差变得非常小,呈现出过拟合的情况.但是交叉验证集的错误将急剧上升,此时的情况是高方差.
直接描述就是:训练集误差小验证集误差大时,就是过拟合-高方差情况;
选择合适的正则化参数lambda
改变lambda时,训练集\(J_{train}\)与交叉验证集\(J_{cv}\)都会发生一定的变化.
当参数过多过大时,后面的正则化项的值就会很大,因而导致$ J()$也变大,从而使这个预测方程得到更多的惩罚,使其像参数变量尽量小的地步靠拢。对正则化过程有影响的是lambda,当lambda数值大的时候,函数收到的惩罚更多,会更快地减少参数数值;当lambda为0的时候,函数则不会对参数进行正则化处理。
如图所示
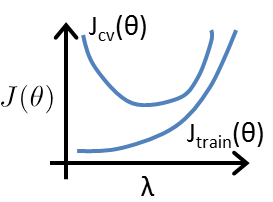
当lambda过大时,会处于高偏差情况,\(J_{train}\)的值会很大,lambda值过小时会处于过拟合情况.
因此,上图的左端对应着高方差,右端对应着高偏差问题,
学习曲线
用于判断算法的学习情况.可以判断此时处于高方差高偏差情况以对于算法进行修改.
绘出\(J_{train}(\theta )\)与\(J_{cv}(\theta )\)的图像.
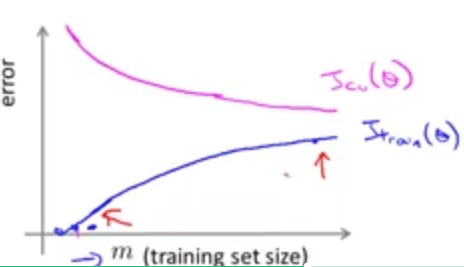
上图为训练集大小与两个J的对应情况.
当训练集过大时,\(J_{train}\)越来越难对与过大的训练集做出良好的拟合,因此在图上表现出m越大error越多.
相反,当训练集大的时候,\(J_{cv}\)更能获得更好的泛化,即对新样品的适应更好,因此可以得到上述曲线.
如果不使用多项式拟合而直接用一条直线,那么数据集的大小再大也于事无补,无法更加接近实际情况.此时\(J_{train}\)与\(J_{cv}\)会很接近,
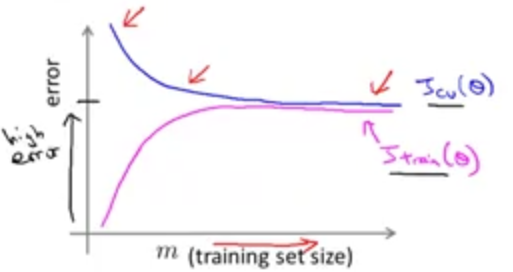
这种情况便是高偏差情况.
反之,如果项数很大的话,学习曲线会如图所示:
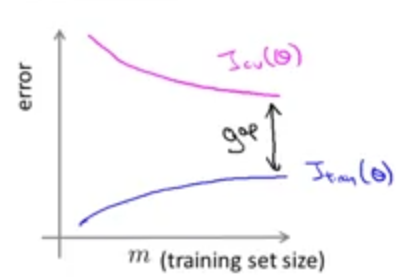
\(J_{train}\)与\(J_{cv}\)间会有很大的差距,这种情况是高方差.
回到最开始的情况
使用更大的训练集可以对于高方差的情况有所帮助(将学习曲线画出来可以看出)
使用更少的特征值可以修复一定的高方差情况.
使用更多的特征值可以修复高偏差情况
使用更高次幂的特征值可以修复高偏差情况
减少正则化参数可以修复高偏差
增加正则化参数可以修复高方差