Python 的多线程与多进程
初学者的并行编程指南
在参加 Kaggle 的 Understanding the Amazon from Space 比赛时,我试图对自己代码的各个部分进行加速。速度在 Kaggle 比赛中至关重要。高排名常常需要尝试数百种模型结构与超参组合,能在一个持续一分钟的 epoch 中省出 10 秒都是一个巨大的胜利。
让我吃惊的是,数据处理是最大的瓶颈。我用了 Numpy 的矩阵旋转、矩阵翻转、缩放及裁切等操作,在 CPU 上进行运算。Numpy 和 Pytorch 的 DataLoader 在某些情况中使用了并行处理。我同时会运行 3 到 5 个实验,每个实验都各自进行数据处理。但这种处理方式看起来效率不高,我希望知道我是否能用并行处理来加快所有实验的运行速度。
什么是并行处理?
简单来说就是在同一时刻做两件事情,也可以是在不同的 CPU 上分别运行代码,或者说当程序等待外部资源(文件加载、API 调用等)时把“浪费”的 CPU 周期充分利用起来提高效率。
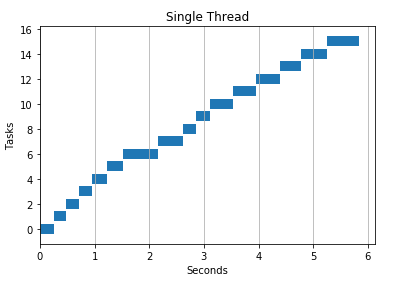
下面的例子是一个“正常”的程序。它会使用单线程,依次进行下载一个 URL 列表的内容。
下面是一个同样的程序,不过使用了 2 个线程。它把 URL 列表分给不同的线程,处理速度几乎翻倍。
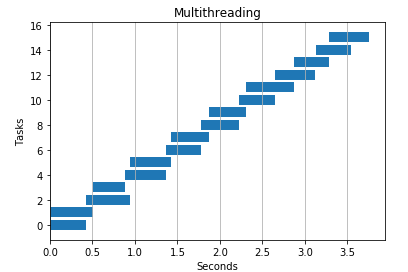
如果你对如何绘制以上图表感到好奇,可以参考源码,下面也简单介绍一下:
- 在你函数内部加上一个计时器,并返回函数执行的起始与结束时间
1 | URLS = [url1, url2, url3, ...] |
- 单线程程序的可视化如下:多次执行你的函数,并将多个开始结束的时间存储下来
1 | results = [download(url, 1) for url in URLS] |
- 将 [start, stop] 的结果数组进行转置,绘制柱状图
1 | def visualize_runtimes(results): |
多线程的图表生成方式与此类似。Python 的并发库一样可以返回结果数组。
进程 vs 线程
一个进程就是一个程序的实例(比如 Jupyter notebook 或 Python 解释器)。进程启动线程(子进程)来处理一些子任务(比如按键、加载 HTML 页面、保存文件等)。线程存活于进程内部,线程间共享相同的内存空间。
举例:Microsoft Word
当你打开 Word
时,你其实就是创建了一个进程。当你开始打字时,进程启动了一些线程:一个线程专门用于获取键盘输入,一个线程用于显示文本,一个线程用于自动保存文件,还有一个线程用于拼写检查。在启动这些线程之后,Word
就能更好的利用空闲的 CPU
时间(等待键盘输入或文件加载的时间)让你有更高的工作效率。
进程
- 由操作系统创建,以运行程序
- 一个进程可以包括多个线程
- 两个进程可以在 Python 程序中同时执行代码
- 启动与终止进程需要花费更多的时间,因此用进程比用线程的开销更大
- 由于进程不共享内存空间,因此进程间交换信息比线程间交换信息要慢很多。在 Python 中,用序列化数据结构(如数组)的方法进行信息交换会花费 IO 处理级别的时间。
线程
- 线程是在进程内部的类似迷你进程的东西
- 不同的线程共享同样的内存空间,可以高效地读写相同的变量
- 两个线程不能在同一个 Python
程序中执行代码(有解决这个问题的方法
*)
CPU vs 核
CPU,或者说处理器,管理着计算机最基本的运算工作。CPU 有一个或着多个核,可以让 CPU 同时执行代码。
如果只有一个核,那么对 CPU 密集型任务(比如循环、运算等)不会有速度的提升。操作系统需要在很小的时间片在不同的任务间来回切换调度。因此,做一些很琐碎的操作(比如下载一些图片)时,多任务处理反而会降低处理性能。这个现象的原因是在启动与维护多个任务时也有性能的开销。
Python 的 GIL 锁问题
CPython(python 的标准实现)有一个叫做 GIL(全局解释锁)的东西,会阻止在程序中同时执行两个线程。一些人非常不喜欢它,但也有一些人喜欢它。目前有一些解决它的方法,不过 Numpy 之类的库大都是通过执行外部 C 语言代码来绕过这种限制。
何时使用线程,何时使用进程?
- 得益于多核与不存在 GIL,多进程可以加速 CPU 密集型的 Python 程序。
- 多线程可以很好的处理 IO 任务或涉及外部系统的任务,因为线程可以将不同的工作高效地结合起来。而进程需要对结果进行序列化才能汇聚多个结果,这需要消耗额外的时间。
- 由于 GIL 的存在,多线程对 CPU 密集的 Python 程序没有什么帮助。
*对于点积等某些运算,Numpy 绕过了 Python 的 GIL
锁,能够并行执行代码。
并行处理示例
Python 的 concurrent.futures 库用起来轻松愉快。你只需要简单的将函数、待处理的对象列表和并发的数量传给它即可。在下面几节中,我会以几种实验来演示何时使用线程何时使用进程。
1 | def multithreading(func, args, |
API 调用
对于 API 调用,多线程明显比串行处理与多进程速度要快很多。
1 | def download(url): |
2 个线程
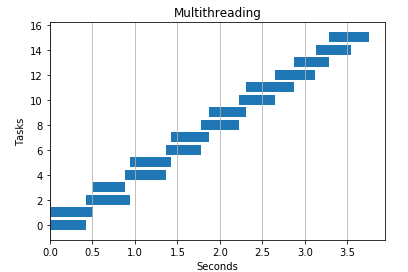
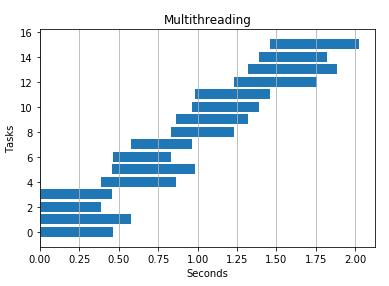
4 个线程
2 个进程
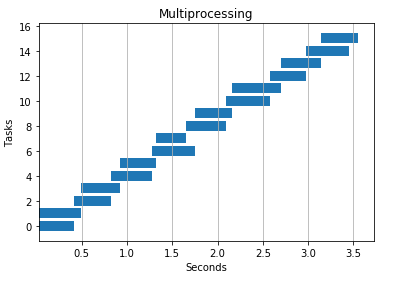
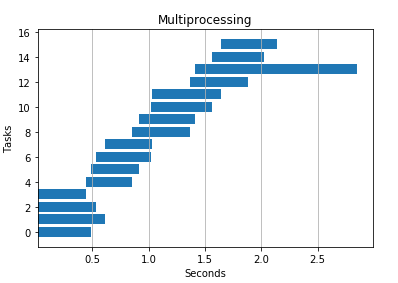
4 个进程
IO 密集型任务
我传入了一个巨大的文本,以观测线程与进程的写入性能。线程效果较好,但多进程也让速度有所提升。
1 | def io_heavy(text): |
串行
1 | %timeit -n 1 [io_heavy(TEXT,1) for i in range(N)] |
4 个线程

4 个进程
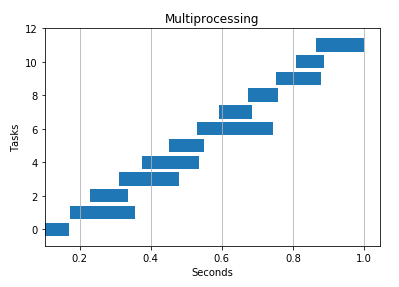
CPU 密集型任务
由于没有 GIL,可以在多核上同时执行代码,多进程理所当然的胜出。
1 | def cpu_heavy(n): |
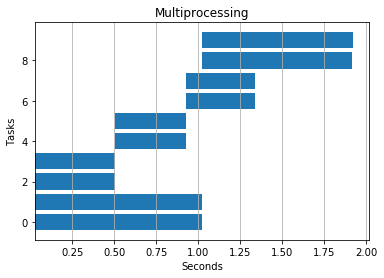
串行: 4.2 秒
4 个线程: 6.5 秒
4 个进程: 1.9 秒
Numpy 中的点积
不出所料,无论是用多线程还是多进程都不会对此代码有什么帮助。Numpy 在幕后执行外部的 C 语言代码,绕开了 GIL。
1 | def dot_product(i, base): |
串行: 2.8 秒
2 个线程: 3.4 秒
2 个进程: 3.3 秒
以上实验的 Notebook 请参考此处,你可以自己来复现这些实验。
相关资源
以下是我在探索这个主题时的一些参考文章。特别推荐 Nathan Grigg 的这篇博客,给了我可视化方法的灵感。
juejin:https://juejin.im/post/5b84f3086fb9a01a1a27cedb#heading-14