Deconvolutional Paragraph Representation Learning
摘要
在许多自然语言处理应用中,从长文本序列中学习其潜在的语义表示是重要的第一步。RNN 已经成为了这个任务的基石。然而,随着文本长度的增加,RNN 的解码重建(decoding、reconstraction)的质量也随之降低。因此,我们提出了一个 seq2seq、由纯粹的卷积与反卷积结构构成的自动编码框架,它没有上述 RNN 的问题,同时计算效率也很高。另外,此方法简单易行,可以在许多应用中作为一块积木使用。我们可以证明,此框架在重构长文本任务中的效果比 RNN 更好。同时,在半监督文本分类及文本摘要任务中的评价指标表明此框架能更好地利用无标注长文本数据。
1 简介
学习句子或多个句子组成的段落是自然语言处理的一项重要任务,它常常是实现其它任务(如情感分析、机器翻译、对话系统、文本摘要等)的基础。从数据中学习句子的表示使用的是编码器 - 解码器结构。在标准的自动编码步骤中,首先由输入序列的 embedding 编码为向量表示,再解码到原始域重建输入序列。近期在 RNN 中,LSTM 及其变体在许多依赖句子表示的学习任务中取得了巨大的成功。
基于 RNN 的方法通常将句子递归建模为含有隐藏单元的马尔可夫过程,其中每个输入句子的单词都是由前一个单词及隐藏单元的状态生成的,通过 emission 与 transition 运算建模为神经网络。原则上,输入序列的神经元表示应当包含了足够的输入序列结构的信息,才能在之后通过解码恢复原句。然而由于 RNN 的递归性质,基于 RNN 将句子完全表示为向量存在着挑战。典型的问题是,RNN 在训练时是基于之前的置信单词的状态来生成序列中的单词,而不是由编码后的向量表示解码整个句子。现在已经证明这种强制性的策略(teacher forcing training)是有必要的,因为它可以让 RNN 的输出接近于置信序列。然而,由于在重建序列时 RNN 允许解码器使用置信信息,削弱了编码器独立生成向量表示的能力,导致编码后的表示没能携带足够的信息来引导解码器在没有其它指引的情况下进行解码。为了解决这个问题,[19] 提出了一种在训练过程中的采样方法,从同时使用潜在表示与置信信号进行学习逐渐转换为仅用编码的潜在表示进行学习。但 [20] 表明,这种计划采样本质上是一种不一致训练策略,在实际使用中会产生不稳定的结果,最终导致训练无法收敛。
在推理时,在遇到无法使用置信信号的句子时,仅能通过前一个单词及表示向量的状态来生成新的单词。此时,解码的错误随着序列长度的增加而成比例增加。这也意味着,在处理句子时,一旦出现一个错误,后续生成的句子将错的更离谱。这种现象是 [19] 中的 exposure bias 产生的。
我们提出了一种简单而强大的纯卷积结构,用于学习句子的表示。比较方便的是,由于这个结构中不含 RNN,因此 teacher forcing training 与 exposure bias 的问题自然就不存在了。这种方法使用 CNN 作为编码器,deCNN 作为解码器。我们认为,这种结构通过多层 CNN 迫使潜在表示从整个句子中提取信息,由此在不适用 RNN 解码器的情况下实现较高的重建质量。这种多层 CNN 能够让表示向量从整个句子中抽取信息而无需考虑句子长度,这也使它可以应用于长句子或段落相关任务。此外,由于这种结构不涉及递归编码及解码,因此可以使用图形处理单元(GPU)的特定卷积原语进行高效并行化,与 RNN 模型相比显著减少了计算成本。
2 自动编码卷积文本模型
2.1 卷积编码器
用 \(w^t\) 表示给定句子中的第 t 个词,将每个词 \(w^t\) 进行 embedding,映射为 k 维的词向量 \(x_t = W_e[w^t]\),其中 $ W_e ^{k V} $ 为一个已经学习好的 Word embedding 矩阵,V 为单词数量;用 $ W_e[v]$ 来表示 \(W_e\) 的第 v 列。\(W_e\) 中的所有列都经过 l2-norm 处理,例如 $ ||W_e[v]||_2 = 1, v $。在经过 embedding 之后,一个长度为 T 的句子(经过 padding)可以在将 embedding 进行 concat 后表示为 \(X \in \mathbb{R}^{k \times T}\);其中 \(x_t\) 为 X 的第 t 列。
对于句子做编码,我们采用了类似 [24] 中的 CNN 结构,这个结构最初是为做图像处理任务设计的。这个 CNN 结构包含 L 个层(L - 1 个卷积层,第 L 层为全连接层),此结构最后可以将一个输入句子转化为一个定长的表示向量 h。层 \(l \in \{1, ... ,L\}\) 由学习到的滤波器 \(p_l\) 组成。对于第一层中的第 i 个滤波器来说,相当于对 X 进行一个步长(stride)为 \(r^{(1)}\)、滤波器为 \(W_c^{(i,1)} \in \mathbb{R}^{k \times h}\) 的卷积运算(式中的 h 代表卷积滤波器的大小)。这一系列操作会生成一个潜在特征映射:\(c^{(i,1)}=\gamma(X * W_c^{(i,1)} + b^{(i,1)}) \in \mathbb{R}^{(T-h)/r^{(1)}+1}\),其中 \(\gamma(.)\) 为非线性激活函数,\(b^{(i,1)} \in \mathbb{R}^{(T-h)/r^{(1)}+1}\) ,* 符号代表了卷积操作。在我们的实验中,\(\gamma(.)\) 为 ReLU。需要注意的是,最初的 embedding 维数 k 在经过第一层卷积层后就发生了变化,\(c^{(i,1)} \in \mathbb{R}^{(T-h)/r^{(1)}+1}\) for i = 1,...,p1。在第一层将 p1 滤波器得到的结果进行拼接,就得到了一个特征映射,\(C^{(1)}= [c^{(1,1)}... c^{(p1,1)}] \in \mathbb{R}^{p_1 \times [(T-h)/r^{(1)}+1]}\)。
在第一个卷积层之后,我们对得到的特征映射 \(C^{(1)}\) 使用同样的滤波器大小 h 进行卷积操作,并在这 L - 1 层中不断重复此操作。每次操作都能将空间维数降低为 \(T^{(l+1)}=[(T^{(l)} - h)/r^{(l)} + 1]\)(\(r^{(l)}\) 为步长,\(T^{(l)}\) 为空间维数大小,l 为第 l 层,[] 为向下取整函数)。在最后一层 L 中,得到了特征映射 \(C^{(L-1)}\),将其送入全连接层中制造潜在表示向量 h。在实现时,我们直接用了一个滤波器大小等于 \(T^{(L-1)}\)(不考虑 h)的卷积层,它就相当于一个全连接层。这个实现上的 trick 在 [24] 中有所使用。这个最后一层将所有的空间坐标 \(T^{(L-1)}\) 汇聚成为标量特征,使用滤波器 \(\{W_c^{(i,l)}\}\) for i=1,...,p1 and l=1,...,L 将句子的子结构依次封装为了向量表示。其中 \(W_c^{(i,l)}\) 表示层 l 的滤波器 i。这也意味着提取出来的特征的维度是固定的,与输入句子的长度无关。
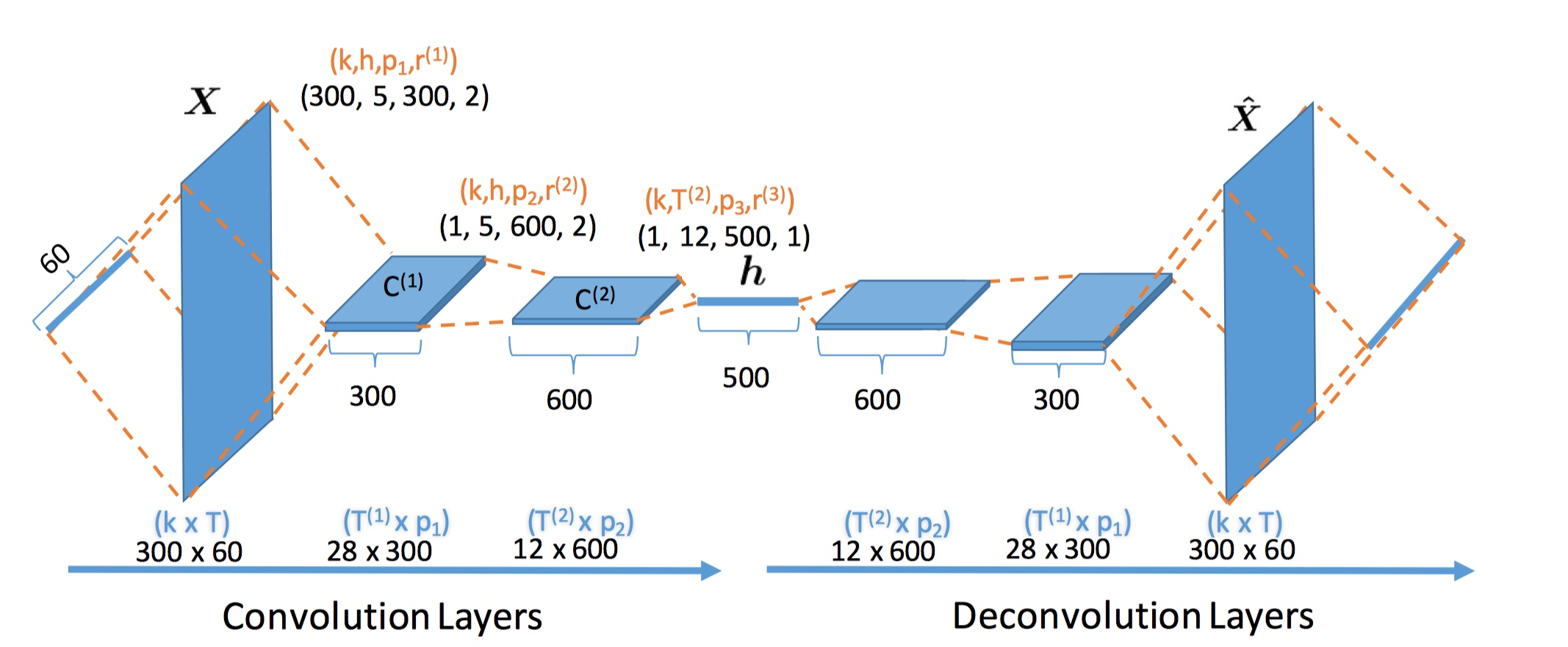
图1,卷积自动编码结构。编码器:将输入序列展开为 embedding 矩阵 X,接着通过多个卷积层编码器压缩为表示向量 h,在最后一层中将向量折叠去除空间维度。解码器:将表示向量 h 送入多个反卷积解码器,以 X 为目标,使用余弦相似度交叉熵损失函数重建 \(\hat{X}\)。
在最后一层有 \(p_L\) 个滤波器,将会构造出 \(p_L\) 维的表示向量。对于输入句子来说,也记为 \(h=C^{(L)}\)。例如,在图一中,编码器由 L=3 个层构成,句子长度为 T=60,embedding 维数为 k=300,不同层的步长 \(\{ r^{(1)},r^{(2)},r^{(3)} \} = \{2,2,1\}\) ,滤波器大小 \(h = \{5,5,12\}\),滤波器数量 \(\{p_1,p_2,p_3 \}=\{300,600,500\}\)。中间层得到的特征映射 \(C^{(1)}\) 和 \(C^{(2)}\) 的大小分别为 \(\{28 \times 300,12 \times 600\}\)。最后的特征映射大小为 1 x 500,对应的正是潜在表示向量 h。
从概念上看,较低层中的滤波器捕捉的是原始的句子信息(h-gram,类似于图像处理中的边缘信息),而叫高层中的滤波器捕捉的是更复杂的语言特征,比如语义和句法结构等(类似于图像处理中的图像元素)。这种自底向上的结构通过分层堆叠文本片段(h-gram)作为构建表示向量 h 的积木。这种方法在思路上类似于通过 concrete syntax trees [26] 对语言的语法结构进行建模。不过,我们没有事先去指定某种语法结构(比如英语),而是通过多层 CNN 网络提取此结构。
2.2 反卷积解码器
我们按照一定步长应用卷积的变体 - 反卷积操作(比如 convolutional transpose),用于解码表示向量 h,将其还原至原来的文本域。随着反卷积的不断进行,向量的空间高度也不断增加,如图1所示,和之前描述的卷积操作刚好相反。空间维数首先展开至与卷积层的 L-1 层相同,接着逐渐展开为 \(T^{(l+1)} = (T^{(l)}-1)*r^{(l)} + h\) for l=1,...直到第 L 个反卷积层(此层与卷积编码器的输入层相对应)。第 L 反卷积层的输出目标是重建 Word embedding 矩阵 \(\hat{X}\)。与 \(W_e\) 一样,\(\hat{X}\) 的每一列都经由 l2-norm 处理。
用 \(\hat{w}^t\) 来表示重建后句子 \(\hat{s}\) 中的第 t 个单词,\(\hat{w}^t\) 为 v 的概率可表示为:
\[p(\hat{w}^t = v) = \frac{\exp[\tau^{-1}D_{cos}(\hat{x}^t,W_e[v])]}{\sum_{v'\in V}\exp[\tau^{-1}D_{cos}(\hat{x}^t,W_e[v'])]}\]
式中,\(D_{cos}(x,y)\) 代表余弦相似度,计算方法为 \(\frac{<{x,y}>}{||x||||y||}\) ,\(W_e[v]\) 是 \(W_e\) 的第 v 列,\(\hat{x}^t\) 是 \(\hat{X}\) 的第 t 列,\(\tau\) 是一个正数,我们将其定义为 temperature parameter [27]。此参数类似于 Dirichlet 分布的浓度参数,控制着概率向量 \([p(\hat{w}^t = 1)...p(\hat{w}^t = V)]\) 的扩散,较大的 \(\tau\) 值会鼓励概率均匀地分布,较小的 \(\tau\) 值会鼓励概率稀疏并集中。在实验中,我们设定 \(\tau = 0.01\)。此外在我们的实验中,余弦相似度可直接由经由 l2-norm 的 \(W_e\) 与 \(\hat{X}\) 内积得到。
2.3 模型学习
上述卷积自动编码器的目标可以记为所有句子(\(s \in D\))的词级别的对数似然:
\[\iota^{\alpha e} = \sum_{d \in D} \sum_t \log p(\hat{w}^t_d = w^t_d)\]
上述式子中,D 表示句子的集合。为了简单起见,使用随机梯度下降对式中的最大对数似然进行优化。实现相关的细节将在实验一节中详细描述。请注意,上述工作与之前的相关工作有两处不同:i) [22,28] 中使用了池化与上池化(pooling,unpooling)操作,而我们用了卷积与反卷积;ii) 更重要的是,[22,28] 没有像我们前面的步骤一样使用余弦相似度来重建句子,而是使用了基于 RNN 的解码器。我们将在第 3 节中更详细地讨论相关工作。在早期的实验(论文中未写出)中,我们使用了池化与上池化,但是没有观察到显著的性能提升;而卷积/反卷积运算则在内存占用方面更具效率。与标准的 LSTM RNN 自动编码器进行对比,两者参数数量大致相同,但我们的结构在单片 NVIDIA TITAN X GPU 上计算速度相当快(详见实验一节)。原因是 CNN 通过 cuDNN 原语处理有着很高的并行效率。
反卷积解码器与 RNN 解码器的对比: 这种结构可以视为 NLP 模型的一种补充结构。与标准的基于 LSTM 的解码器相反,反卷积与 RNN 的区别在于它有着不严格的序列依赖性。具体来说,RNN 生成一个单词需要一个隐藏单元的向量,以递归的方式在整句中顺序地积累信息(长效信息主要依赖于向下权重);而反卷积解码器,解码时的生成仅依赖一个封装了整个句子信息的表示向量,没有指定顺序结构。因此,对于语言生成任务,RNN 解码器会比反卷积解码器生成相关性更好的文本;与之相反,反卷积解码器在计算长句、远距离依赖的情况效果更好,因此在分类特征提取与文本摘要任务中更加有用。
2.4 半监督分类与摘要
识别相关主题或情绪以及从用户生成的内容(如博客、产品评论等)生成摘要最近获得了大量的关注[1, 3, 4, 30, 31, 13, 11]。在大多数实际情况下,未标注数据非常丰富,但实际上很少能充分发挥这些未标注数据的潜力。以此为契机,我们希望能补充一些稀缺但更有价值的标注数据,以提高监督学习模型的泛化能力。无论是标注数据还是未标注数据,上述模型可以通过提取未标注数据,学习它们的潜在表示,捕获其语义信息。这可以将任务分为两步,在监督训练之前进行上述步骤。近期,应用这种思路的基于 RNN 的方法已经被广泛使用,并在许多任务中获得了 state-of-the-art 的效果 [1, 3, 4, 30, 31]。此外,还可以构建一个分类器与自动编码解码器联合的分类模型,对潜在向量表示 h 进行分类,详见 [32, 33]。
又比如,在产品评论中,每个评论可能包含了数百个词,这对基于 RNN 的序列编码器来说有着一定的困难。因为 RNN 需要在文本中滑动并抽取信息,这会导致信息的丢失,在长句子中更为严重[34]。另外,在训练过程中解码用到了置信的真实信息,这可能导致无法完全保留来自输入文本的所有信息,而这些丢失的信息对于重建句子、分类、摘要来说是至关重要的。
我们考虑将这个卷积自动编码解码结构应用于长句、段落的半监督学习任务中。我们将半监督问题视作 [35] 中的多任务学习问题,同时训练序列编码器与监督模型,而不是像 [1, 3] 中那样预训练无监督模型。理论上来说,这种联合训练方法得到的段落 embedding 向量会保持重建与分类的能力。
3 相关工作
之前的工作 [22, 28, 21, 38, 39] 已经考虑了将 CNN 用作为一些 NLP 任务的编码器了。一般来说,基于 CNN 的编码器结构会使用一个单一的卷积层再加上池化层。这种结构在给定卷积滤波窗口大小为 h 时,实质上就是做了一个识别特定 h-gram 结构的检测器。从原理看,我们这种架构中的深层结构可以让高层学习到更复杂的语言特征。
4 实验
实验结果图:



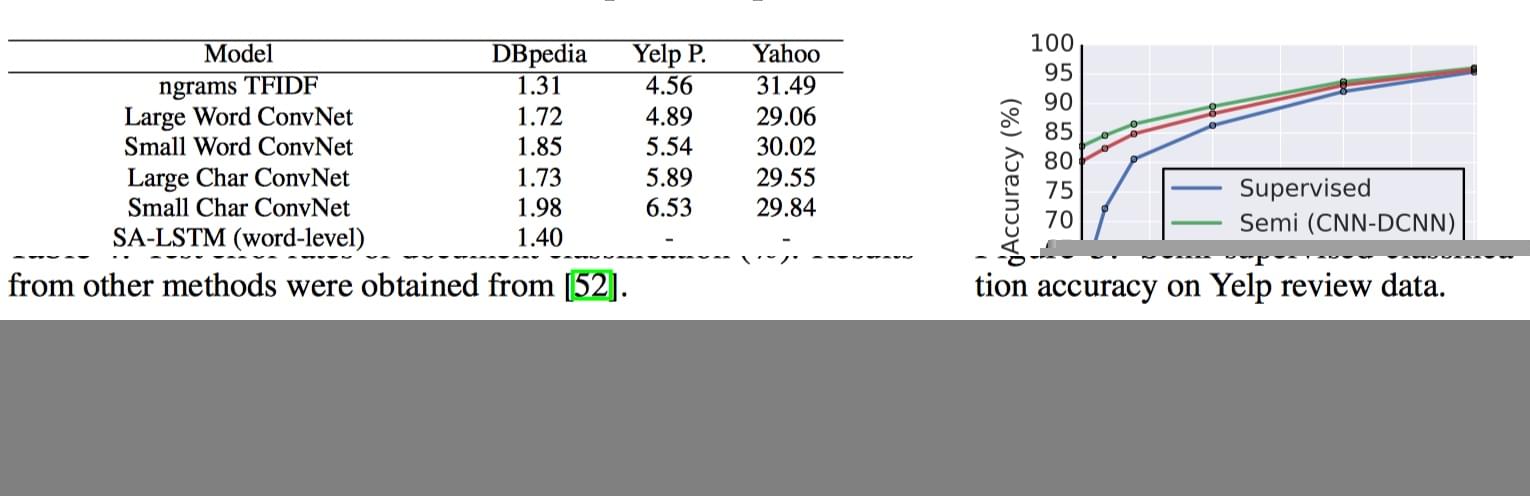
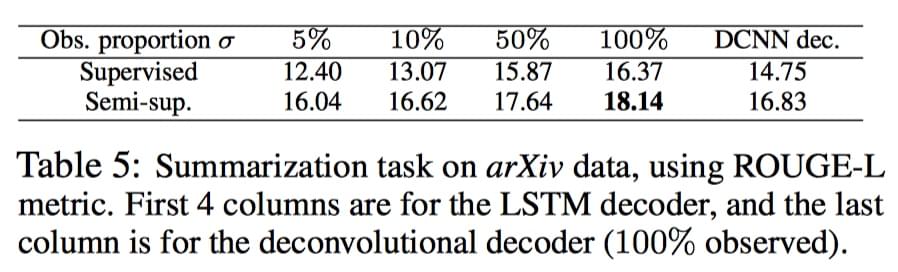
5 结论
我们提出了一种只使用卷积与反卷积运算的用于文本模型的通用结构。这种结构没有进行序列条件生成,因此避免了 teacher forcing training 与 exposure bias 问题。这种方法可以将段落完全压缩至潜在表示向量中,此向量也能解压缩重建原始输入序列。总的来说,这种方法实现了高质量的长段落重建,并优于现有的拼写矫正算法、半监督序列分类算法、文本摘要算法,且减少了计算成本。
引用
[1] Andrew M Dai and Quoc V Le. Semi-supervised sequence learning. In NIPS, 2015.
[2] Quoc Le and Tomas Mikolov. Distributed representations of sentences and documents. In ICML, 2014.
[3] Rie Johnson and Tong Zhang. Supervised and Semi-Supervised Text Categorization using LSTM for Region Embeddings. arXiv, February 2016.
[4] Takeru Miyato, Andrew M Dai, and Ian Goodfellow. Adversarial Training Methods for Semi-Supervised Text Classification. In ICLR, May 2017.
[5] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural Machine Translation by Jointly Learning to Align and Translate. In ICLR, 2015.
[6] Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. In EMNLP, 2014.
[7] Fandong Meng, Zhengdong Lu, Mingxuan Wang, Hang Li, Wenbin Jiang, and Qun Liu. Encoding source language with convolutional neural network for machine translation. In ACL, 2015.
[8] Tsung-Hsien Wen, Milica Gasic, Nikola Mrksic, Pei-Hao Su, David Vandyke, and Steve Young. Semantically conditioned lstm-based natural language generation for spoken dialogue systems. arXiv, 2015.
[9] Jiwei Li, Will Monroe, Alan Ritter, Michel Galley, Jianfeng Gao, and Dan Jurafsky. Deep reinforcement learning for dialogue generation. arXiv, 2016.
[10] Jiwei Li, Will Monroe, Tianlin Shi, Alan Ritter, and Dan Jurafsky. Adversarial learning for neural dialogue generation. arXiv:1701.06547, 2017.
[11] Ramesh Nallapati, Bowen Zhou, Cicero Nogueira dos santos, Caglar Gulcehre, and Bing Xiang. Abstractive Text Summarization Using Sequence-to-Sequence RNNs and Beyond. In CoNLL, 2016.
[12] Shashi Narayan, Nikos Papasarantopoulos, Mirella Lapata, and Shay B Cohen. Neural Extractive Summarization with Side Information. arXiv, April 2017.
[13] Alexander M Rush, Sumit Chopra, and Jason Weston. A Neural Attention Model for Abstractive Sentence Summarization. In EMNLP, 2015.
[14] Ilya Sutskever, Oriol Vinyals, and Quoc V Le. Sequence to sequence learning with neural networks. In NIPS, 2014.
[15] Tomas Mikolov, Martin Karafiát, Lukas Burget, Jan Cernock`y, and Sanjeev Khudanpur. Recurrent neural network based language model. In INTERSPEECH, 2010.
[16] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. In Neural computation, 1997.
[17] Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv, 2014.
[18] Ronald J Williams and David Zipser. A learning algorithm for continually running fully recurrent neural networks. Neural computation, 1(2):270–280, 1989.
[19] Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. Scheduled sampling for sequence prediction with recurrent neural networks. In NIPS, 2015.
[20] Ferenc Huszár. How (not) to train your generative model: Scheduled sampling, likelihood, adversary? arXiv, 2015.
[21] Nal Kalchbrenner, Edward Grefenstette, and Phil Blunsom. A convolutional neural network for modelling sentences. In ACL, 2014.
[22] Yoon Kim. Convolutional neural networks for sentence classification. In EMNLP, 2014.
[23] Ishaan Gulrajani, Kundan Kumar, Faruk Ahmed, Adrien Ali Taiga, Francesco Visin, David Vazquez, and Aaron Courville. Pixelvae: A latent variable model for natural images. arXiv, 2016.
[24] Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv, 2015.
[25] Vinod Nair and Geoffrey E Hinton. Rectified linear units improve restricted boltzmann machines. In ICML, pages 807–814, 2010.
[26] Ian Chiswell and Wilfrid Hodges. Mathematical logic, volume 3. OUP Oxford, 2007.
[27] Emil Julius Gumbel and Julius Lieblein. Statistical theory of extreme values and some practical applications: a series of lectures. 1954.
[28] Ronan Collobert, Jason Weston, Léon Bottou, Michael Karlen, Koray Kavukcuoglu, and Pavel Kuksa. Natural language processing (almost) from scratch. In JMLR, 2011.
[29] Sharan Chetlur, Cliff Woolley, Philippe Vandermersch, Jonathan Cohen, John Tran, Bryan Catanzaro, and Evan Shelhamer. cudnn: Efficient primitives for deep learning. arXiv, 2014.
[30] Zichao Yang, Diyi Yang, Chris Dyer, Xiaodong He, Alex Smola, and Eduard Hovy. Hierarchical attention networks for document classification. In NAACL, 2016.
[31] Adji B Dieng, Chong Wang, Jianfeng Gao, and John Paisley. TopicRNN: A Recurrent Neural Network with Long-Range Semantic Dependency. In ICLR, 2016.
[32] Diederik P Kingma, Shakir Mohamed, Danilo Jimenez Rezende, and Max Welling. Semi-supervised learning with deep generative models. In NIPS, 2014.
[33] Yunchen Pu, Zhe Gan, Ricardo Henao, Xin Yuan, Chunyuan Li, Andrew Stevens, and Lawrence Carin.
Variational autoencoder for deep learning of images, labels and captions. In NIPS, 2016.
[34] Sepp Hochreiter, Yoshua Bengio, Paolo Frasconi, and Jürgen Schmidhuber. Gradient flow in recurrent nets: the difficulty of learning long-term dependencies, 2001.
[35] Richard Socher, Jeffrey Pennington, Eric H Huang, Andrew Y Ng, and Christopher D Manning. Semisupervised recursive autoencoders for predicting sentiment distributions. In EMNLP. Association for Computational Linguistics, 2011.
[36] Samuel R Bowman, Luke Vilnis, Oriol Vinyals, Andrew M Dai, Rafal Jozefowicz, and Samy Bengio. Generating sentences from a continuous space. arXiv, 2015.
[37] Zichao Yang, Zhiting Hu, Ruslan Salakhutdinov, and Taylor Berg-Kirkpatrick. Improved Variational Autoencoders for Text Modeling using Dilated Convolutions. arXiv, February 2017.
[38] Baotian Hu, Zhengdong Lu, Hang Li, and Qingcai Chen. Convolutional neural network architectures for matching natural language sentences. In NIPS, 2014.
[39] Rie Johnson and Tong Zhang. Effective use of word order for text categorization with convolutional neural networks. In NAACL HLT, 2015.
[40] Jost Tobias Springenberg, Alexey Dosovitskiy, Thomas Brox, and Martin Riedmiller. Striving for simplicity: The all convolutional net. arXiv, 2014.
[41] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015.
[42] Stanislau Semeniuta, Aliaksei Severyn, and Erhardt Barth. A Hybrid Convolutional Variational Autoencoder for Text Generation. arXiv, February 2017.
[43] Nal Kalchbrenner, Lasse Espeholt, Karen Simonyan, Aaron van den Oord, Alex Graves, and Koray Kavukcuoglu. Neural machine translation in linear time. arXiv, 2016.
[44] Yann N Dauphin, Angela Fan, Michael Auli, and David Grangier. Language Modeling with Gated Convolutional Networks. arXiv, December 2016.
[45] J. Gehring, M. Auli, D. Grangier, D. Yarats, and Y. N. Dauphin. Convolutional Sequence to Sequence Learning. arXiv, May 2017.
[46] Aaron van den Oord, Nal Kalchbrenner, Lasse Espeholt, Oriol Vinyals, Alex Graves, et al. Conditional image generation with pixelcnn decoders. In NIPS, pages 4790–4798, 2016.
[47] Jiwei Li, Minh-Thang Luong, and Dan Jurafsky. A hierarchical neural autoencoder for paragraphs and documents. In ACL, 2015.
[48] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representations of words and phrases and their compositionality. In NIPS, 2013.
[49] Kam-Fai Wong, Mingli Wu, and Wenjie Li. Extractive summarization using supervised and semi-supervised learning. In ICCL. Association for Computational Linguistics, 2008.
[50] Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. In ACL workshop, 2004.
[51] Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In ACL. Association for Computational Linguistics, 2002.
[52] Xiang Zhang, Junbo Zhao, and Yann LeCun. Character-level convolutional networks for text classification. In NIPS, pages 649–657, 2015.
[53] Dzmitry Bahdanau, Philemon Brakel, Kelvin Xu, Anirudh Goyal, Ryan Lowe, Joelle Pineau, Aaron Courville, and Yoshua Bengio. An actor-critic algorithm for sequence prediction. arXiv, 2016.
[54] JP Woodard and JT Nelson. An information theoretic measure of speech recognition performance. In Workshop on standardisation for speech I/O, 1982.
[55] Diederik Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In ICLR, 2015.
[56] Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feedforward neural networks. In AISTATS, 2010.