从 Gzip 压缩 SVG 说起 — 论如何减小资源文件的大小
文件越小,意味着下载速度就越快。因此在向客户端发送资源文件前,使文件变得更小是件有益的事情。
其实,精简与压缩资源文件不仅是一件很棒的事情,同时也是每一位现代开发者应该尽量去做的事情。但是,用于精简的工具通常无法做到完美精简;用于压缩的压缩器效果好坏会取决于用于压缩的数据。下面介绍一些小技巧与方法,用于调整这些工具,使其达到最好的工作状态。
准备工作
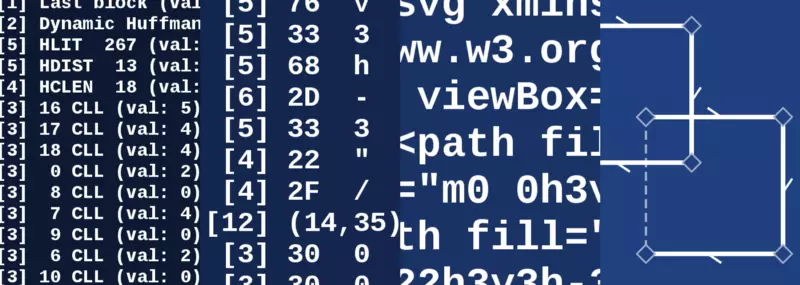
我们将以一个简单的 SVG 文件为例:

这个<svg>图像的内容为一个 10x10
像素的区域(viewBox),其中包含了两个 6x6
的正方形(<rect>)。原始文件大小为 176 字节,经过
gzip 压缩过后大小为 138 字节。
当然这个图像并没有什么艺术感,但它足以满足这篇文章想要表达的意思,并且防止这篇文章变成长篇大论。
第 0 步:Svgo
运行 svgo image.svg 直接进行压缩。

(为了便于阅读,为其添加了回车与缩进)
可以明显地看到,rect 被替换成了
path。path 路径形状由它的 d
属性定义,后面的一串命令类似于 canvas 的 draw
函数,控制一支虚拟的笔移动进行绘画。命令可以是绝对位移(移动到
x,y),也可以是相对位移(向某方向移动
x,y)。请仔细观察其中的一条路径:
M 0 0:路径起点为坐标(0, 0)
h 6:水平向右移动 6 px v 6:垂直向下移动 6 px
H 0:水平移动至 x = 0 z:闭合路径
— 移回路径的起点
这个路径画出的正方形是多么的精确!而且它比 rect
元素更加的紧凑。
另外,#f00 被改成了
red,这儿也少了一个字节!
现在文件大小为 135 字节,gzip 压缩过后为 126 字节。
第 1 步:进行整体缩放
你可能已经注意到了,两个路径中的所有坐标均为偶数。我们是否可以把它们都除以 2 呢?

图像和之前看起来是一样的,但它缩小了两倍。因此,我们可以对
viewBox 进行缩放,使图像与之前一样大。

现在文件大小为 133 字节,gzip 压缩过后为 124 字节。
第 2 步:使用非闭合路径
回过头来看路径。两个路径中的最后一个命令都是
z,也就是“闭合路径”。但路径在填充的时候会被隐式地闭合,因此我们可以删除这些命令。

又少了 2 字节,现在文件大小为 131 字节,gzip 压缩过后为 122 字节。从常识上说,原始字节数越少,能压缩的大小也越小。而现在我们已经在 svgo 之后节省了 4 个 gzip 字节了。
你可能会想:为什么 svgo 不自动进行这些优化呢?原因是缩放图像与删除尾部的 z 命令是不安全的。请看下面的例子:

这是一些有 stroke(路径宽度)的图形。从左至右分别为:原始图形、不闭合的情况、不闭合且进行缩放的情况。
线宽完全混乱了。庆幸的是,我们知道自己不需要使用线宽。但是 Svgo 并不知道这个情况,因此它必须要保证图形的安全,避免不安全的变换。
现在看起来不能从代码中删除任何东西了。XML 语法是严格的,现在所有的属性都是必须的,并且它们的值不能不加引号。
你以为结束了?并不,这仅仅是个开始。
第 3 步:减少出现的字母
现在,让我来介绍一个非常方便的工具:gzthermal。它可以分析需要进行 gzip 压缩的文件,并对进行编码的原始字节进行着色。更好压缩的字节是绿色,不好压缩的数据是红色,简单明了。

请再次关注 d 属性,尤其是被标成红色的 M
命令值得注意。我们不能删除它,但我们可以用相对位移 m2 2
来代替它。
初始的“指针”位置为坐标轴原点(0, 0),因此移动到(2, 2)和从原点移动(2, 2)是同一个意思。让我们试试:


原始文件依然是 131 字节,但是经过 gzip 压缩过后大小仅有 121 字节了。发生了什么?答案是……
哈夫曼树(Huffman Trees)
Gzip 使用的是 DEFLATE 压缩算法,而 DEFLATE 算法是以哈夫曼树为基础构建的。
哈夫曼编码的核心思想就是使用更少的比特对出现次数更多的符号进行编码,反之亦然,出现次数很少的符号需要占用更多的比特。
没错,这儿说的是比特不是字节。DEFATE 算法会将一字节的字符视为一系列的比特,无论一字节包含 7、9、100 个比特,DEFLATE 算法都能一视同仁。
以字符串“Test”为例,根据它出现的字母来进行编码: 00 T
01 e 10 s 11 t
对每个符号都进行过编码的字符串“Test”可以表示为:00011011,总共占
8 比特。
然后我们把它开头的“T”改成小写“test”,再试一次: 0 t
10 e 11 s
字母 t 出现了更多的次数,它的编码也变得更短,仅为 1
比特。这个字符串经过编码后为 010110,仅为 6 比特!
在我们的 SVG 中的 M 字母也一样。在将其变为小写之后,整个编码中都不包含大写的 M 了,可以将它从树上移除,因此平均编码长度可以更短。
当你编写对 gzip 友好的代码时,应该更多地使用那些使用频率较高的字符。即使你不能将代码长度减短,但它经过压缩后消耗的比特数也会变少。
第 4 步:回退引用(backreferences)
DEFLATE 算法还有一个特性:回退引用。某些编码点不会直接进行编码,而是告诉解码器复制一些最近解码的字节。
因此,它不需要对原始字节一次又一次地进行编码,而是可以直接引用: 向前返回 n 个字节,复制 m 个字节 例如:
Hey diddle diddle, the cat and the fiddle.
Hey diddle**<7,7>**, the cat and**<12,5>**f**<24,5>**.
巧妙的是,gzthermal 还有一种只显示回退引用的特殊模式。
gzthermal -z 会显示以下图像:

普通文本字节为橙色,可回退引用的字节为蓝色。下面的动画更直观:

除了 fill 值、m 命令和最后的 H
命令外,第二条路径几乎全部都使用了回退引用。对于 fill 和 m
我们无能为力,因为第二个方块的确有着不同的颜色和位置。
但是它们的形状是一样的,并且我们现在对 gzip
有了更加清晰的认识。因此,我们可以将绝对位移命令 H0 和
H2 都替换为相对位移命令:h-3。


现在,两个分开的回退引用合为了一个,文件大小为 133 字节,gzip 后的大小为 119 字节。虽然我们在压缩前增加了 2 个字节,但 gzip 的结果又减少了 2 个字节!
我们只需要关心压缩后的大小即可:在传送资源时,客户端 99.9% 用的是 gzip 或者 brotli。顺带说一下 brotli。
Brotli 压缩算法
Brotli 是于 2015 年推出的用于替换浏览器中 gzip(源自 1992)的算法。不过它与 gzip 在很多方面都有相似之处:它也是基于哈夫曼编码与回退引用的原理,因此我们前面为 gzip 所做的调整都可以同样利于 Brotli。最后让我们用 Brotli 应用于前面的所有步骤:
原始文件大小:106 字节 在第 0 步之后(svgo):104 字节 在第 1 步之后(viewBox):105 字节 在第 2 步之后(使用非闭合路径):113 字节 在第 3 步之后(小写 m):116 字节 在第 4 步之后(相关命令):102 字节
如你所见,最终的文件比 svgo 后的更小。这可以说明,之前我们为 gzip 做的酷炫的工作同样适用于 Brotli。
但是,中间步骤的文件大小却是混乱的,Brotli 压缩后的文件变得更大了。毕竟,Brotli 并不是 gzip,它是一种单独的新算法。尽管与 gzip 有一些相似之处,但仍有所不同。
其中最大的不同是,Brotli 内置了预定义字典,在编码时使用它进行上下文启发。此外,Brotli 的最小回退引用大小为 2 字节(gzip 仅能创建 3 字节及以上的回退引用)。
可以说,Brotli 比 gzip 更加难以预测。我很想解释一下是什么导致了“压缩退化”,可惜 Brotli 并没有类似于 gzip 的 gzthermal 和 defdb 之类的工具。我只能靠它的规范 以及试错的方法来进行调试。
试错法
让我们再试一次。这次将改变 fill 属性内的颜色。显然
red 比 #f00 更短,但也许 Brotli
会用更长的回退引用进行压缩。

gzip 压缩过后大小为 120 字节,Brotli 压缩过后为 100 字节。gzip 流长了 1 字节,Brotli 流短了 2 字节。
此时,它在 Brotli 中表现更好,在 gzip 中表现更差。我觉得,这完全无碍!因为我们几乎不可能一次性将数据针对所有压缩器进行优化,并得到最佳结果。解决压缩器问题就像转一个糟糕的魔方,只能尽量优化。
总结
上面描述的所有的调整方法都不仅限于 SVG 压缩为 gzip 的情景。
以下是一些可以帮助你写出更具备压缩性能的代码的准则:
- 压缩更小的源数据可能会得到更小的压缩数据。
- 不同的字符越少就意味着熵越少。而熵越小,压缩效果就越好。
- 频繁出现的字符会以更小的字节被压缩。删除不常见字符以及使常见字符更常见可以提高压缩效率。
- 长段重复的代码可以被压缩成几个字节。DRY(“不要重复自己”原则)不一定在任何情况下都是最好的选择,有时候重复自己反而能得到更好的结果。
- 有些时候更大的源数据反而可以得到更小的压缩数据。减少熵可以让压缩器更好地移除冗余的信息。
你可以在 此 GitHub repo 中找到以上所有资源、压缩过的图片以及其它资料。
希望你喜欢这篇文章。下次我们将讨论如何压缩普通 JavaScript 代码与 Webpack bundle 中的 JavaScript 代码。
本文发布于掘金 https://juejin.im/post/5a30a7fdf265da4309452517