Information Extraction in Illicit Web Domains 论文笔记
Kejriwal M, Szekely P. Information Extraction in Illicit Web Domains[J]. 2017.
论文信息
论文作者为南加大维特比学院的 Mayank Kejriwal 和 Pedro Szekely,发表于 WWW 2017。
论文概述
建立了稳定可靠的信息提取系统(Information Extraction System),用以从非法领域的网页中抽取有用的实体信息。将建立的模型应用于真实数据集得到的结果比 baseline(设定为 CRF)的 F-Score 高了 18%。
论文提纲
- 论文简介
- 描述了一些 IE system 的相关工作
- 详细描述了此文章所使用的模型
- 实验评估
- 总结工作
一、论文简介
作者首先简介了构建领域知识图谱(knowledge graph)所需要做的工作:
领域发现。来源可以为爬虫或领域本体库。 > 爬虫部分引用了 S. Chakrabarti. Mining the Web: Discovering knowledge from hypertext data. Elsevier, 2002. > 领域本体库部分引用了 A. Zouaq and R. Nkambou. A survey of domain ontology engineering: methods and tools. In Advances in intelligent tutoring systems, pages 103–119. Springer, 2010.
有了数据源后,使用 IE system 抽取相关结构化数据。作者简述了基于统计学习的信息抽取方法:使用 CRF 序列标注、以及在数据量大的情况下使用深层神经网络,目的为抽取命名实体与关系(extraction of name entities and relationships)。 > 神经网络部分引用 R. Collobert and J. Weston. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th international conference on Machine learning, pages 160–167. ACM, 2008.
当 IE system 在跨领域 Web 数据源(cross-domain Web source,以维基百科为例)和传统领域(以生物学为例)表现优秀时,在一些“动态领域”(dynamic domain)中表现一般。这些领域包括:news feed、自媒体、广告、在线市场以及一些非法领域(如人口贩卖 human trafficking)等。
非法领域的信息抽取之所以难做是因为在非法网站中常常会对信息进行混淆、非随机地对一些常用词进行错误拼写、OOV(out of vocabulary,非登录词)及生僻词高频出现、有时候还非随机使用Unicode 字符,且相关网页中正文分布稀疏、网页结构各异。与传统领域中(如聊天记录、Twitter 等)规律的信息不同,这些信息正文在非法网站中基本上是独一无二的。此论文仅讨论人口贩卖领域,不过在另一些在暗网中存在 Web 服务的非法领域(如武器贩卖、恐怖袭击、假货等)也可以适用。
接着举了两个典型例子说明上面的情况: eg1. Hey gentleman im neWYOrk and i’m looking for generous... eg2. AVAILABLE NOW! ?? - (4 two 4) six 5 two - 0 9 three 1 - 21
因此传统领域 IE system 的包装归纳学习系统(wrapper induction systems)不能在这些领域中正常工作,只能将数据给调查员和领域专家进行分析。 作者归纳:此论文分析了传统的 IE system 在动态的、非法的领域中的不适用性,因此提出了一种不依赖于传统信息提取系统、可在小样本 Web 数据集上正常运行的方法。
简介这种方法。此方法包含了两个步骤:
- 第一步,使用召回率很高的识别器(用于识别地址、年龄等)为所有页面做候选标注(candidate annotations)。如下图所示
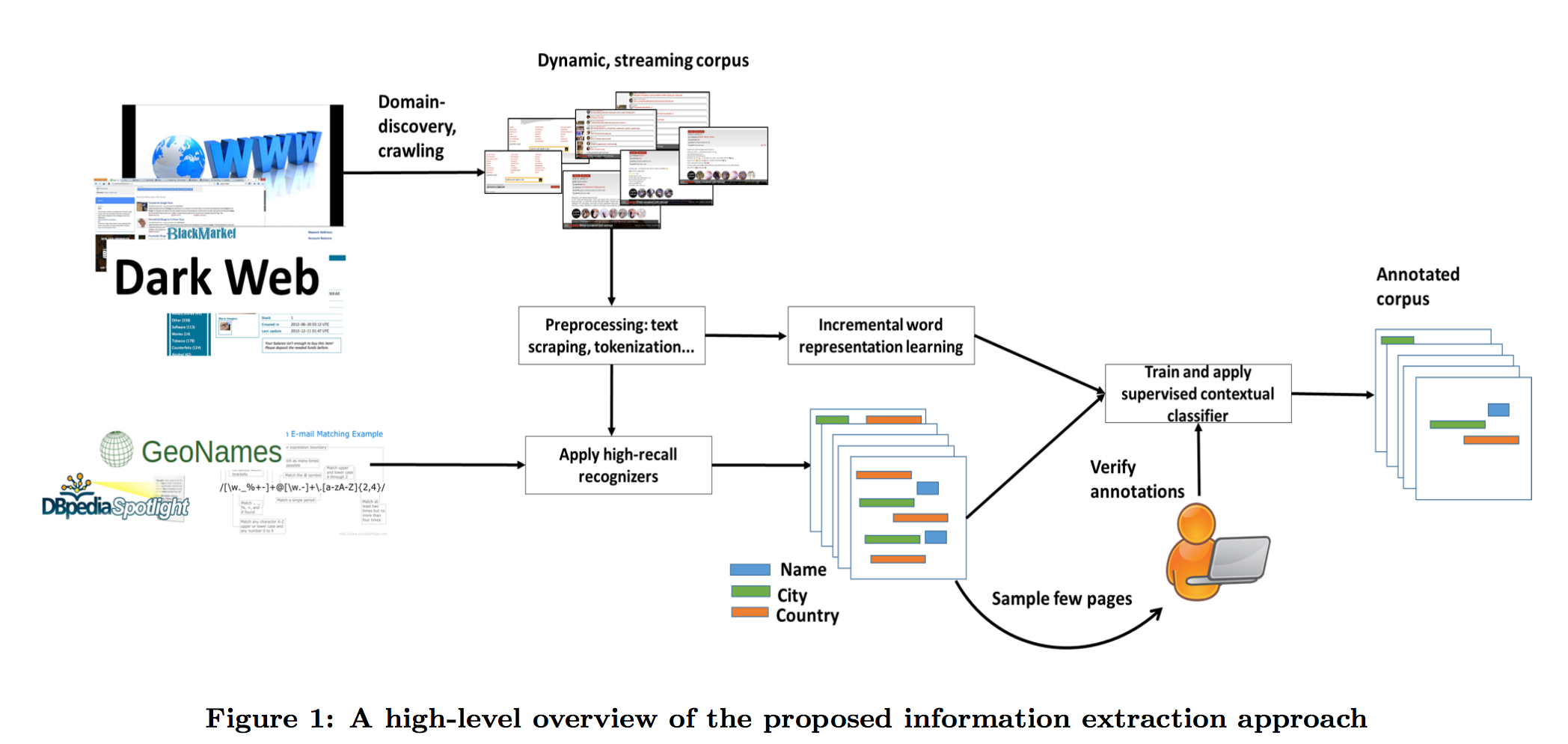
- 第二步,使用一种无特征的监督学习算法,基于随机映射学习单词表示的意思。用此算法对上面的候选标注进行二分类,分为正确与不正确。
- 简述贡献:创建了一种轻量级的、无特征的信息提取系统,可以适用于各种各样的非法领域。且这种方法很容易实现,无需大范围地调参,效果随数据集增大而增强,适用部署于流数据。且此方法在刚开始做领域发现的小数据集上也表现良好,在遇到超大 web 数据集时依然稳定。
- 简述 baseline,基于 CRF 的最新的 Stanford Named Entity Resolution system,包含关于人口贩卖的预训练数据。
二、相关工作
Open IE > N. Kushmerick. Wrapper induction for information extraction. PhD thesis, University of Washington, 1997. > M. Banko, M. J. Cafarella, S. Soderland,M. Broadhead, and O. Etzioni. Open information extraction from the web. In IJCAI, volume 7, pages 2670–2676, 2007. ADRMine > B. Han, P. Cook, and T. Baldwin. Text-based twitter user geolocation prediction. Journal of Artificial Intelligence Research, 49:451–500, 2014. > A. Nikfarjam, A. Sarker, K. OaˆA ̆Z ́Connor, R. Ginn, and G. Gonzalez. Pharmacovigilance from social media: mining adverse drug reaction mentions using sequence labeling with word embedding cluster features. Journal of the American Medical Informatics Association, page ocu041, 2015.
在此之前还没有工作对无特征、低监督的 web 非法领域信息提取进行研究。
三、方法
总体的架构如上图 Figure 1 所示。模型有两个输入端,一个是包含有关兴趣领域的 Web 页面集,一个是有着高召回率的识别器。在此论文中假定模型初始化时的数据集很小,接着会有很多的数据不断地加入到数据集中(即模仿流数据条件)。首先将给定一个初始的数据集,其中已经人工标注好了 10-100 条数据的属性(假定为城市、姓名、年龄),模型将根据此数据集在没有做特征工程的情况下学习出一个信息提取系统。 > 此处数据条数有疑问
需要注意的是需要分析的 Web 页面大多是多领域结合,因此在处理页面时不仅需要不断将新的页面加入数据集中,还要由初始数据集进行概念漂移(concept drift)以适应各种新的情况。
1 预处理过程
爬取相关网页,使用 RTE(Readability Text Extractor)对 HTML 文本进行正文提取。对 RTE 进行调参,将其调至高召回率。由于 Web 网页的结构多样,因此正文中可能会存在许多无关内容(包括一些无用的数字及 Unicode 字符等等)。RTE 最终会返回一组字符串集,字符串集中包含以句子为单位的内容。 > RTE 给了网址:https://www.readability.com/developers/api
接下来使用 NLTK 对 RTE 返回内容的每个句子分别进行分词。
2 词向量表示
接下来作者使用 CRF 序列标注模型对已标注数据进行学习(详细内容在后面)。但是由于数据集实在太少,CRF 的效果并不好。 为了避免 CRF 出现的状态,又为了避免工作量极大的页面标注,作者使用了非监督算法,以低维空间来表示页面中所有词的全集。在此使用了嵌入算法(embedding algorithms),作者在此提及了 Word2Vec 和 Bollegala 的算法和一种更简单的算法(random indexing)。 > Word2Vec 引用了 T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems, pages 3111–3119, 2013. > Bollegala 算法引用了 D. Bollegala, T. Maehara, and K.-i. Kawarabayashi. Embedding semantic relations into word representations. arXiv preprint arXiv:1505.00161, 2015. > random indexing 引用了 M. Sahlgren. An introduction to random indexing. In Methods and applications of semantic indexing workshop at the 7th international conference on terminology and knowledge engineering, TKE, volume 5, 2005. 最终作者选用了“最简单”的 RI(random indexing)算法。此算法可以保证向量在表示时,即使是在低维空间中点与点间依然能够保持足够的距离。RI 算法最开始本来是为了增量降维(incremental dimensionality reduction)设计的。RI 算法定义如下:
\(d \in \mathbb{Z}^+\) -> 向量维数 \(r \in [0,1]\) -> 定义为 +1 或 -1 的概率
对于一个词向量(这里应该叫做 token 向量,因为在这个情景中 nltk 并不能很好地进行正确分词)来说,随机选择 \([d * r]\) 个维度设定为 +1,随机选择 \([d * r]\) 个维度设定为 -1,其余 \(d - 2 [d * r]\) 个维度设定为 0。
由于在此场景下数据均为噪音很多的流数据,因此只考虑较短的上下文范围。由此确定 RI 算法的滑动窗口大小。滑动窗口定义如下:
给定一组数量为 \(|t|\) 的单位元素 \(t\),以及一个窗口基准位置 \(0 < i < |t|\),则可以定义一个滑动窗口 \((u, v)\)。滑动窗口内的所有元素记为 \(S\),将基准位置的特征词挖去:\(S - t[i]\),得到滑动窗口全集。滑动窗口的位置坐标为 \([max(i-u,1),min(i+v,|t|)]\)。
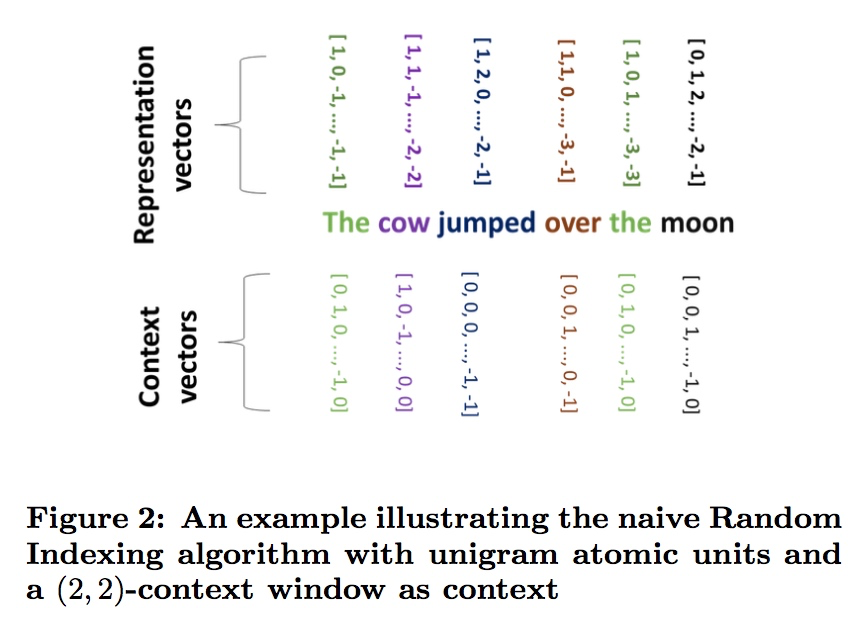
上图为使用 RI 算法,设定滑动窗口大小设定为 (2,2) 时产生的 Token 向量。
作者对于原始的 RI 算法进行了一些改进,改动内容如下:
原始 RI 算法在求某特征词上下文向量时没有进行任何权重计算,直接对上下文非特征词的词向量进行了求和。也就是说,对于单词 w 来说,其表示向量进行了 \(\vec{w}_{i+1} = \vec{w}_i + \vec{a}\) 计算。但是对于非法领域来说,在此情景中会出现大量独特的 token ,包括且不仅限于罕见单词、Unicode 符号、HTML tag、数字序列(如电话号码)等。这些 token 可能在文本全集中仅仅会出现一次或少数几次,因此它们产生的表示向量也会很少出现。作者为了避免这种情况的出现,预先定义了一些“高权重单位”(compound unit)
为了定义这种高权重单位的值,作者对于上下文中 token 可能出现的一些“罕见”情况进行了定义,定义如下:
| Name | 名称 | 描述 |
|---|---|---|
| High-idf-units | 低词频单元 | 单元内的单词词频低于设定值\(\theta\)(默认为 1%) |
| Pure-num-units | 纯数字单元 | 只包含数字的单元 |
| Alpha-num-units | 字母-数字混合单元 | 至少包含 1 个数字与 1 个字母的单元 |
| Pure-punct-units | 纯符号单元 | 只包含标点符号的单元 |
| Alpha-punct-units | 字母-符号混合单元 | 至少包含 1 个字母与 1 个符号的单元 |
| Nonascii-unicode-units | 非 ASCII 字符单元 | 只包含非 ASCII 字符的单元 |
以上 6 种“罕见”的单元就是“高权重单位”。
作者在这儿举了个例子:有个单词为“rare”它在文中出现的词频低于某个设定值(如 1%),它根据上表可以定义为 High-idf-units。
作者对 RI 算法根据上面的定义进行了一定修改:RI 算法在计算上下文向量时,仅使用上面 6 中高权重单元的表示向量进行计算。也就是说,每个 token 最终都可以根据上面 6 中高权重单元的向量的线性计算得到自己的独特向量 \(\vec{w}_C\)。
个人认为作者这样做丢失了很多可能会有用的信息,但是这样可以在本来整体信息就不多的非法领域网页 Web 正文中最大可能地提取高敏感信息。如果之后对这种方法进行改进的话,可以在这块找出更多高敏感信息的模式特征,或者使用改造过的 word2vec 等其它算法进行尝试。
3 应用高召回率识别器
此处的“识别器”指的是对单一属性进行识别的函数。作者在此给出了相关定义:
对于某个属性 A,它的识别器 \(R_A\) 为一个函数,该函数接受一组 token,该组数据记为 t。给定两个输入值 i 与 j(\(j \geq i\)),分别代表 t 中的两个位置。如果 t 的 t[i]:t[j] 子集为 A 属性的 instance 则返回 True,否则返回 False。
值得注意的是在上面的定义中,识别器并不能识别出 token 中所隐藏的 instance。在平常的 IE system 中所使用的识别器一般都是 recall 和 precision 都相对较高的。在现在这个情境中,识别器不再追求纯粹的准确率(评判标准为 recall 与 precision),而是尽量少丢失一些信息。因此作者选用了有着高 recall 的识别器对文本进行识别标注,在后面一步再去使用监督学习分类来改进这一步产生的候选标注的 precision。
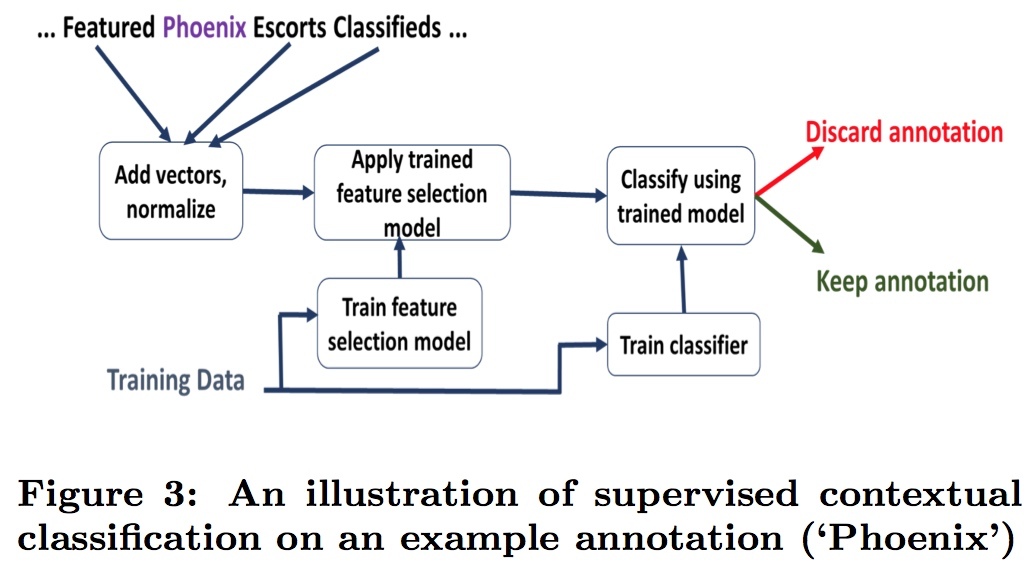
4 使用监督学习根据上下文进行分类
在此之前,已经通过高 recall 的识别器将大多数有可能正确的有意义实体给识别出来,因此需要应用分类器对前一步骤得到的各个实体进行分类以提高最终结果精确度。
由识别器得到一系列的标注(标注可以为单独的 token,也可以是一组连续的 token),将各个标注所在的滑动窗口 (u,v)-context 取出其上下文,求其向量表示,上下文向量的无权重和(unweighted sum)来表示这些标注的上下文向量。
接着,对这些向量应用 l2 正则,使用监督学习分类器(如随机森林)对其进行分类。
四、实验评估
1 数据集与评价标准
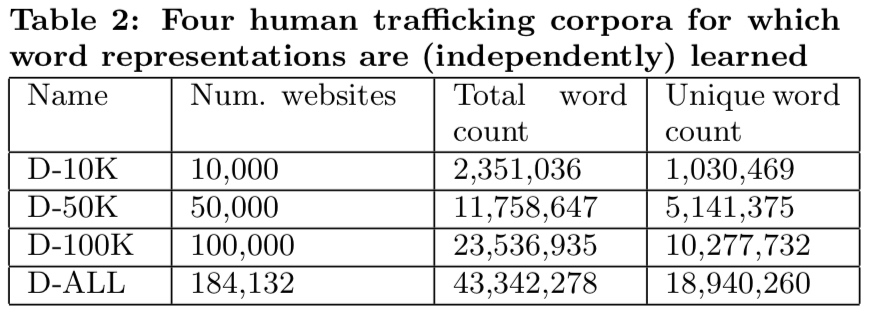
表 2:数据集用量
作者描述,数据集来自于 DARPA MEMEX 项目。(网址:http://www.darpa.mil/program/memex)
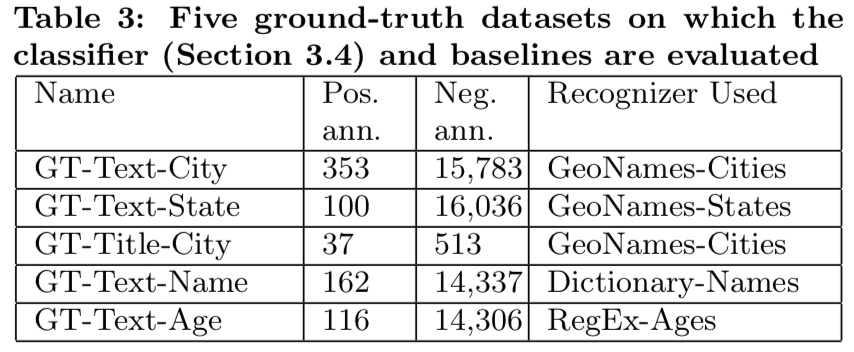
表 3:5 种类别的标准数据集
baseline 与本文的分类器都将对上表包含的 5 种类型的数据进行分类标注。
本文的标准数据集来自于数据集。对数据集应用高 recall 识别器,再对识别器得到的结果进行人工标注。
2 系统描述
根据上文所述,本文构建的 Information Extraction System 对于每种属性都由两个部分组成:高 recall 识别器与用于裁剪标记的分类器。作者实验室为此构建了 4 中高 recall 的识别器,分别为:
GeoNames-Cities GeoNames-States RegEx-Ages Dictionary-Names
其中前两种识别器的数据集来自于http://www.geonames.org/,在此处引用了 M. Wick and C. Boutreux. Geonames. GeoNames Geographical Database, 2011。
对于年龄识别,开发了 https://github.com/usc-isi-i2/dig-age-extractor > 阅读代码发现原理特别简单,单纯的匹配数字
对于姓名属性,作者收集了各种语言的姓名于数据集中,数据集地址: https://github.com/usc-isi-i2/dig-dictionaries/tree/master/person-names
3 baseline
作者使用 Stanford Named Entity Recognition system(NER) 作为其 baseline。 > 此处引用 J. R. Finkel, T. Grenager, and C. Manning. Incorporating non-local information into information extraction systems by gibbs sampling. In Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics, pages 363–370. Association for Computational Linguistics, 2005.
并使用为其使用了一个预训练数据集(脚标 12)。对于新数据集使用 baseline 模型进行重训练,随机采样 30% 与 70% 数据集作为训练集,其余数据作为测试集。baseline 的设置如下表所示:
 表
4:斯坦福 NER 在模型重训练时的参数设置
表
4:斯坦福 NER 在模型重训练时的参数设置
4 相关参数
词向量表示中,使用 100 维,低词频词的词频比例阈值设为 0.01。(这些参数作者说是根据之前的相关论文设定的,但是在这儿没有引用具体论文)。滑动窗口大小设置为 (2,2),作者在此描述尝试使用了更大的滑动窗口但是没有很好的效果。
分类器采用随机森林分类,树数量为 10,变量重要性度量方式为 Gini 指数法,找出最佳的 20 个特征进行分类,使用 ANOVA(方差分析)作为评估函数。
评估指标:准确率、回归率与 F1 指标
实验环境:iMac,4GHz Intel core i7,32 GB RAM,Scikit-learn v0.18
5 实验结果
直接贴论文中实验结果的指标表格:
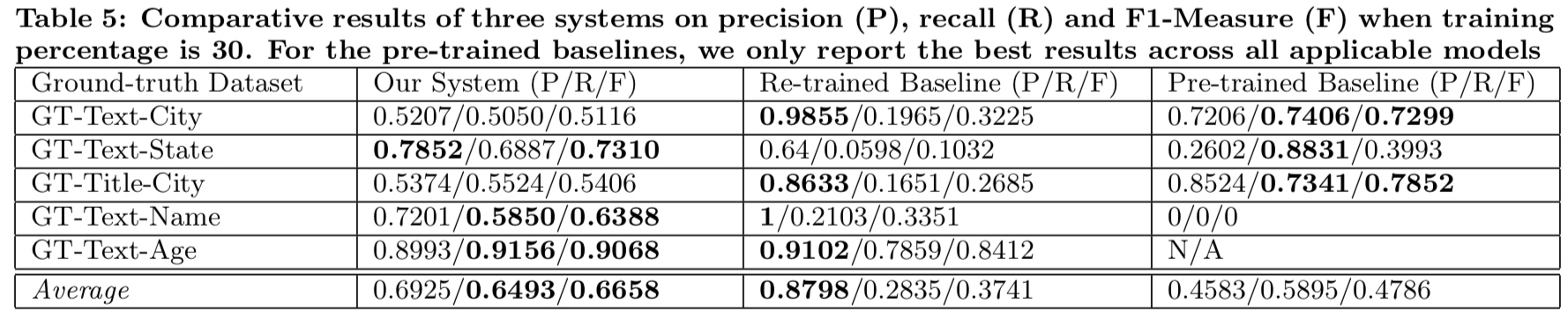
表 5:baseline 与此系统在训练 30% 数据时的 PRF 指标

表 6:baseline 与此系统在训练 70% 数据时的 PRF 指标
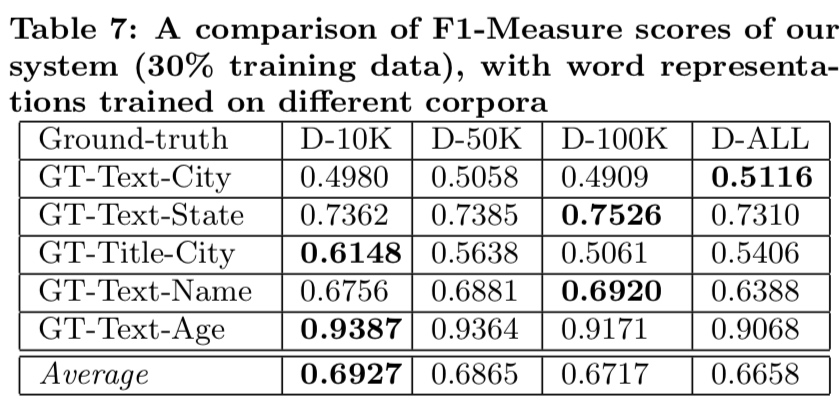
表 7:训练 30% 数据时,此系统在不同全集中的 F1 指标
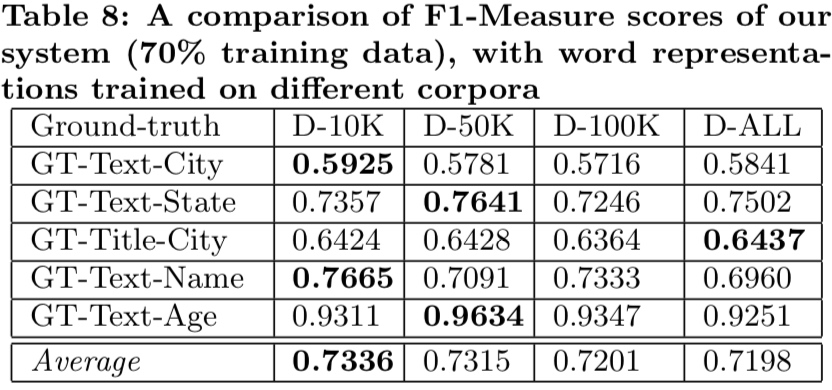
表 8:训练 70% 数据时,此系统在不同全集中的 F1 指标
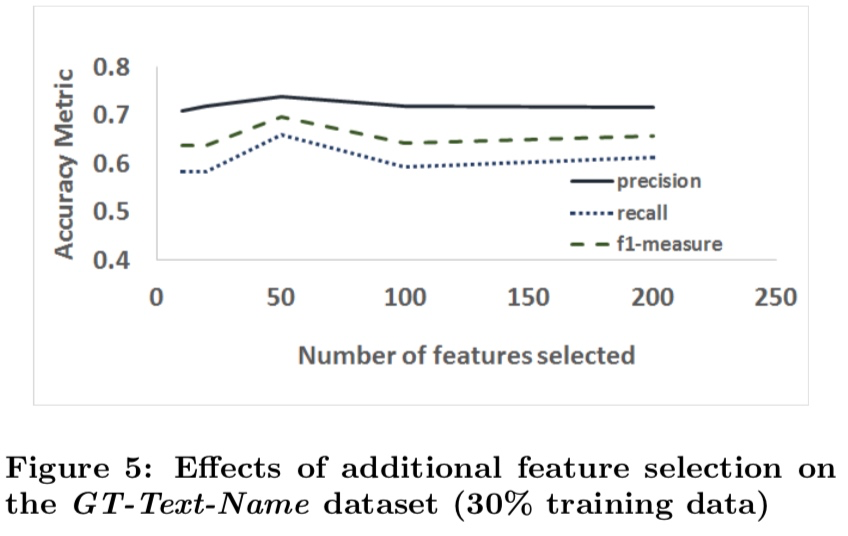
图 5:训练 30% 数据时,在姓名属性识别中,使用不同特征数量得到的 PRF 指标变化折线图

表 9:系统识别城市名称的一些样例
6 讨论
(作者”解释“了前面我关于为什么不使用 word2vec 的疑惑)作者表示,他也不清楚为啥不能使用 word2vec 之类更具适应性的算法来代替 Random Indexing 算法。不过表 7 与表 8 可以看到 Random Indexing 算法在不断加入更多网站的情况下表现仍然稳定。

表 10:在一万数据集与全集中 Random Indexing 算法找到的相似语义样例
由表 10 可以看到 Random Indexing 算法在不同数据集大小下表现的鲁棒性,给出的相似语义词依然较为准确。
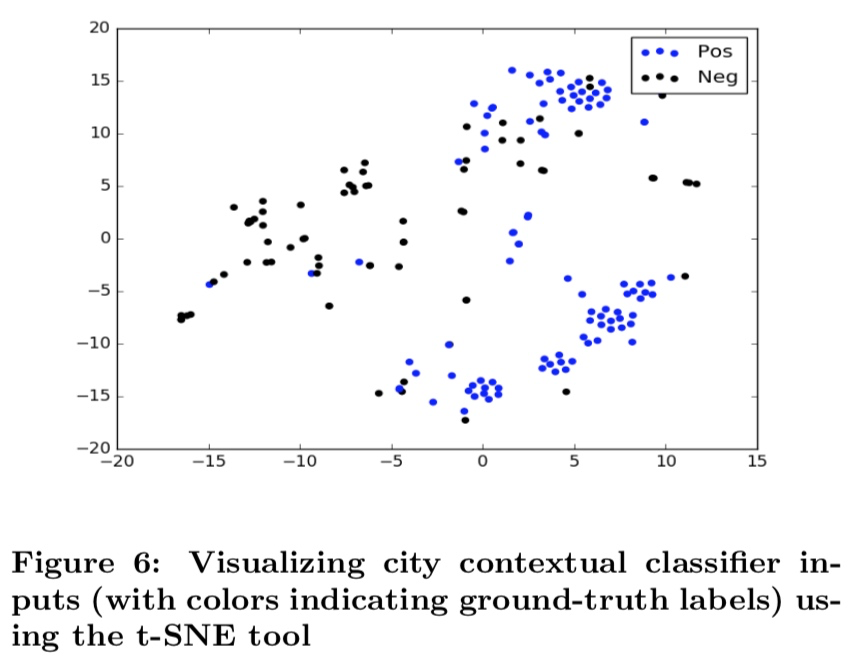
图 6:城市名称上下文分类时的可视化图(不同的颜色表示在标准数据集中的标签)
使用 t-SNE 工具对数据进行可视化,得到上图。 > t-SNE 工具引用了 L. v. d. Maaten and G. Hinton. Visualizing data using t-sne. Journal of Machine Learning Research, 9(Nov):2579–2605, 2008.
由图可见,分类器对城市名称正负例分类效果良好。另外可以观察到图中有许多点各自又组成了一些”子聚类“(sub-cluster),这些点来自于上下文比较相似的数据。
最后,作者表示他们在后来的工作中对一些不常见的属性(例如一些领域特定属性)进行了测试,仍然得到了相似的性能。因此这种方法在各种情况都适用。
总结
作者提出了一种轻量、特征不可知的信息提取方式,适用于非法 Web 领域。这种方法基于初始本体集中构建的向量表示,与使用高 recall 的分类器结合,得到了良好的结果。实验结果表明这种方法相对于其 baseline(CRF)有明显的提升。论文中的各种代码都在 github 上进行了公开。