使用 AI 为 Web 网页增加无障碍功能

图为一位盲人正在阅读盲文(图片链接)
根据世界健康组织的统计,全球约有 2.85 亿位视力障碍人士,仅美国就有 810 万网民患视力障碍。
在我们视力正常的人看来,互联网是一个充满了文字、图片、视频等事物的地方,然而对于视力障碍人士来说却并不是这样的。有一种可以读出网页中文字和元数据的工具叫做屏幕阅读器,然而这种工具的作用十分有限,仅能让人看到网页的一部分文本。虽然一些开发人员花时间去改进他们的网站,为视障人士添加图片的描述性文字,但是绝大多数程序员都不会花时间去做这件公认冗长乏味的事情。
所以,我决定做这么一个工具,来帮助视障人士通过 AI 的力量来“看”互联网。我给它起名为“Auto Alt Text”(自动 Alt 文本添加器),是一个 Chrome 拓展插件,可以让用户在图片上点击右键后得到场景描述 —— 最开始是要这么做的。
您可以观看 这个视频,了解它是如何运作的,然后 下载它并亲自试一试吧!!
为什么我想做 Auto Alt Text:
我曾经是不想花时间为图片添加描述的开发者中的一员。对那时的我来说,无障碍永远是“考虑考虑”的事,直到有一天我收到了来自我的一个项目的用户的邮件。

邮件内容如下:“你好,Abhinav,我看了你的 flask-base 项目,我觉得它非常适合我的下个工程。感谢你开发了它。不过我想让你知道,你应该为你 README 中的图片加上 alt 描述。我是盲人,用了很长一段时间才弄清楚它们的内容 :/来自某人”
在收到邮件的时候,无障碍功能的开发是放在我开发队列的最后面的,基本上它就是个“事后有空再添加”的想法而已。但是,这封邮件唤醒了我。在互联网中,有许多的人需要无障碍阅读功能来理解网站、应用、项目等事物的用途。
“现在 Web 中充满了缺失、错误或者没有替代文本的图片” —— WebAIM(犹他州立大学残疾人中心)
用 AI(人工智能)来挽救:
现在其实有一些方法来给图像加描述文字;但是,大多数方法都有一些缺点:
- 它们反应很慢,要很长时间才能返回描述文字。
- 它们是半自动化的(即需要人类手动按需标记描述文字)。
- 制作、维护它们需要高昂的代价。
现在,通过创建神经网络,这些问题都能得到解决。最近我接触、学习了 Tensorflow —— 一个用于机器学习开发的开源库,开始深入研究机器学习与 AI。Tensorflow 使开发人员能够构建可用于完成从对象检测到图像识别的各种任务的高鲁棒模型。
在做了一些研究之后,我找到了一篇 Vinyals 写的论文《Show and Tell: Lessons learned from the 2015 MSCOCO Image Captioning Challenge》。这些研究者们创建了一个深度神经网络,可以以语义化方式描述图片的内容。

im2txt 的实例来自 im2txt Github Repository
im2txt 的技术细节:
这个模型的机制相当的精致,但是它基本上是一个“编码器 - 解码器”的方案。首先图片会传入一个名为 Inception v3 的卷积神经网络进行图片分类,接着编码好的图片送入 LSTM 网络中。LSTM 是一种专门用于序列模型/时间敏感信息的神经网络层。最后 LSTM 通过组合设定好的单词,形成一句描述图片内容的句子。LSTM 通过求单词集中每个单词在句子中出现的似然性,分别计算第一个词出现的概率分布、第二个词出现的概率分布……直到出现概率最大的字符为“.”,为句子加上最后的句号。
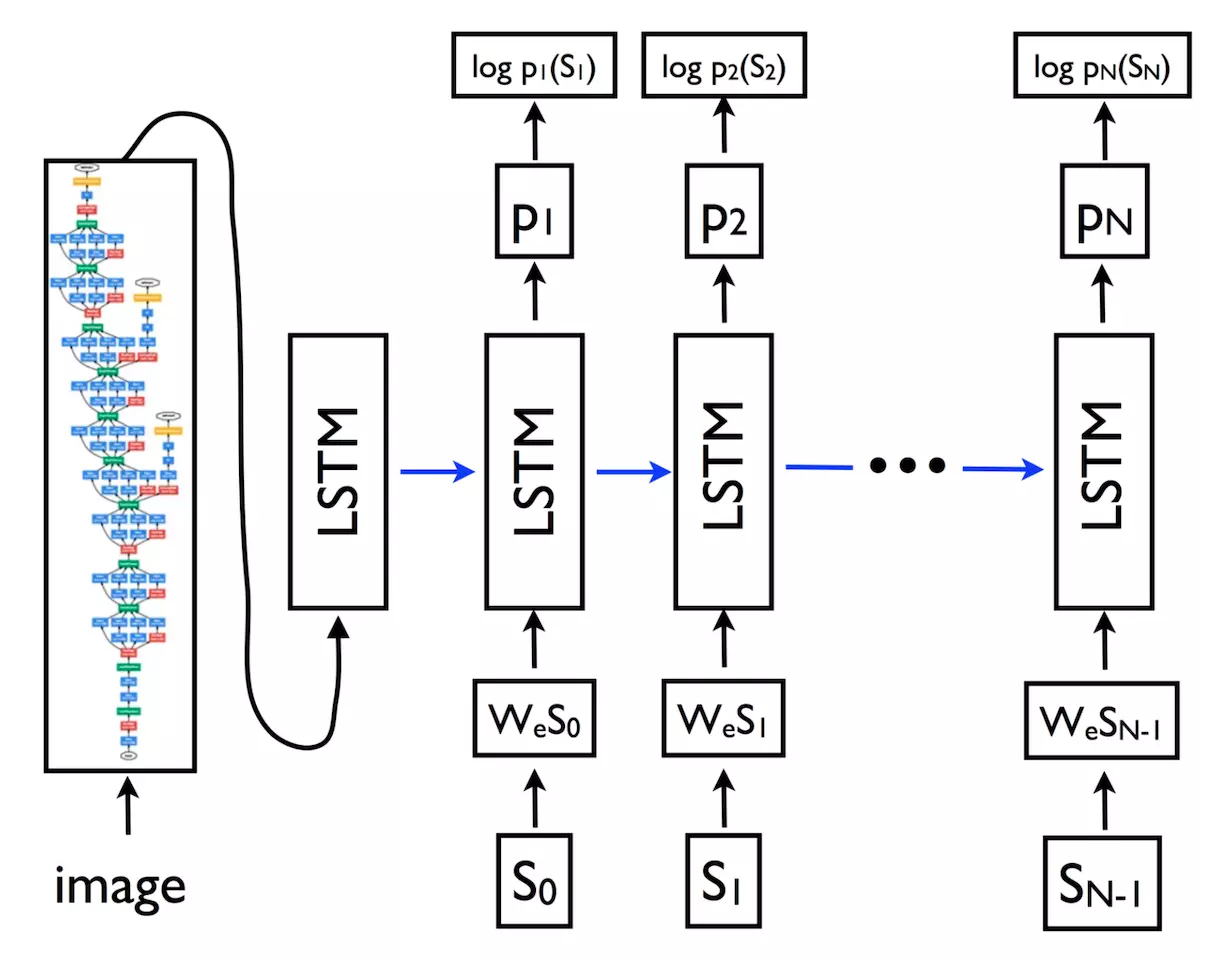
图为此神经网络的概况(图片来自 im2txt Github repository)
根据 Github 库中的说明,这个模型在 Tesla k20m GPU 上的训练时间大约为 1-2 周(在我笔记本的标准 CPU 上计算需要更多的时间)。不过值得庆幸的是,Tensorflow 社区提供了一个已经训练好的模型。
使用 box + Lamdba 解决问题:
在运行模型时,我试图使用 Bazel 来运行模型(Bazel 是一个用于将 tensorflow 模型解包成可运行脚本的工具)。但是,当命令行运行时,它需要大约 15 秒钟的时间才能从获取一张图片的结果!解决问题的唯一办法就是让 Tensorflow 的整个 Graph 都常驻内存,但是这样需要这个程序全天候运行。我计划将这个模型挂在 AWS Elasticbeanstalk 上,在这个平台上是以小时为单位为计算时间计费的,而我们要维持应用程序常驻,因此并不合适(它完全匹配了前面章节所说的图片描述软件缺点的第三条缺点)。因此,我决定使用 AWS Lambda 来完成所有工作。
Lambda 是一种无服务器计算服务,价格很低。此外,它会在计算服务激活时按秒收费。Lambda 的工作原理很简单,一旦应用收到了用户的请求,Lambda 就会将应用程序的映象激活,返回 response,然后再停止应用映象。如果收到多个并发请求,它会唤起多个实例以拓展负载。另外,如果某个小时内应用不断收到请求,它将会保持应用程序的激活状态。因此,Lambda 服务非常符合我的这个用例。

图为 AWS API Gateway + AWS = ❤️ (图片链接)
使用 Lambda 的问题就在于,我必须要为 im2txt 模型创建一个 API。另外,Lambda 对于以功能形式加载的应用有空间限制。上传整个应用程序的 zip 包时,最终文件大小不能超过 250 MB。这个限制是一个麻烦事,因为 im2txt 的模型就已经超过 180 MB 了,再加上它运行需要的依赖文件就已经超过 350 MB 了。我尝试将程序的一部分传到 S3 服务上,然后在 Lambda 实例运行再去下载相关文件。然而,Lambda 上一个应用的总存储限制为 512 MB,而我的应用程序已经超过限制了(总共约 530 MB)。
为了减小项目的大小,我重新配置了 im2txt,只下载精简过的模型,去掉了没用的一些元数据。这样做之后,我的模型大小减小到了 120 MB。接着,我找到了一个最小依赖的 lambda-packs,不过它仅有早期版本的 python 和 tensorflow。我将 python 3.6 语法和 tensorflow 1.2 的代码进行了降级,经过痛苦的降级过程后,我最终得到了一个总大小约为 480 MB 的包,小于 512 MB 的限制。
为了保持应用的快速响应,我创建了一个 CloudWatch 函数,让 Lambda 实例保持”热“状态,使应用始终处于激活态。接着,我添加了一些函数用于处理不是 JPG 格式的图片,在最后,我做好了一个能提供服务的 API。这些精简工作让应用在大多数情况下能够于 5 秒之内返回 response。
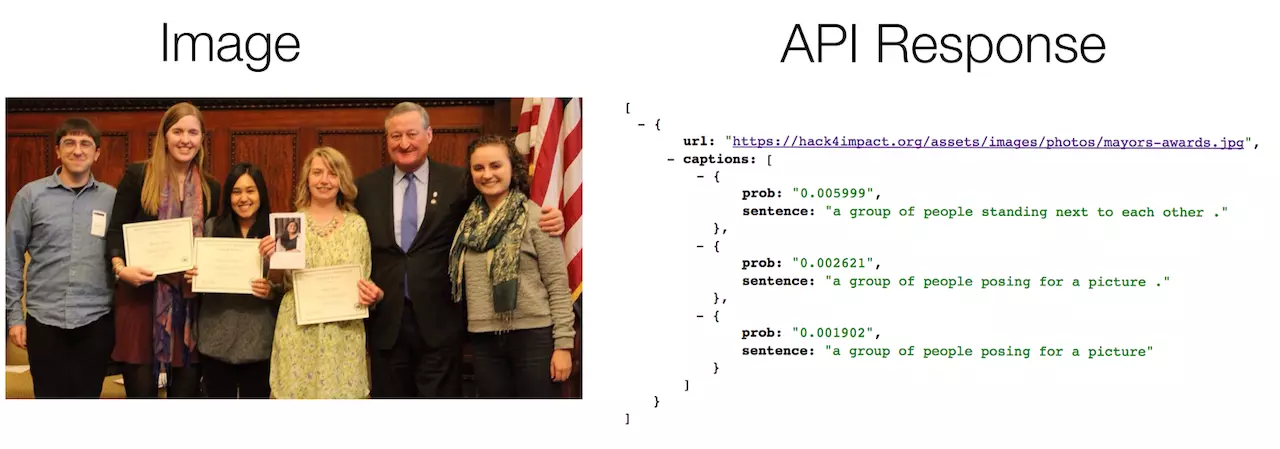
上图为 API 提供的图片可能内容的概率
此外,Lambda 的价格便宜的令人惊讶。以现在的情况,我可以每个月免费分析 60,952 张图片,之后的图片每张仅需 0.0001094 美元(这意味着接下来的 60,952 张图像约花费 6.67 美元)。
有关 API 的更多信息,请参考 repo:https://github.com/abhisuri97/auto-alt-text-lambda-api
剩下的工作就是将其打包为 Chrome 拓展插件,以方便用户使用。这个工作没啥挑战性(仅需要向我的 API 端点发起一个简单的 AJAX 请求即可)。

上图为 Auto Alt Text Chrome 插件运行示例
结论:
Im2txt 模型对于人物、风景以及其它存在于 COCO 数据集中的内容表现良好。

上图为 COCO 数据集图片分类
这个模型能够标注的内容还是有所限制;不过,它能标注的内容已经涵盖了 Facebook、Reddit 等社交媒体上的大多数图片。
但是,对于 COCO 数据集中不存在的图片内容,这个模型并不能完成标注。我曾尝试着使用 Tesseract 来解决这个问题,但是它的结果并不是很准确,而且花费的时间也太长了(超过 10 秒)。现在我正在尝试使用 Tensorflow 实现 王韬等人的论文,将其加入这个项目中。
总结:
虽然现在几乎每周都会涌现一些关于 AI 的新事物,但最重要的是退回一步,看看这些工具能在研究环境之外发挥出怎样的作用,以及这些研究能怎样帮助世界各地的人们。总而言之,我希望我能深入研究 Tensorflow 和 in2txt 模型,并将我所学知识应用于现实世界。我希望这个工具能成为帮助视障人士”看“更好的互联网的第一步。
相关链接:
- 关注文章作者:我会在 Medium 上首发我写的文章。如果你喜欢这篇文章,欢迎关注我:)。接下来一个月,我将会在下个月发布一系列“如何使用 AI/tensorflow 解决现实世界问题”的文章。最近我还会发一些 JS 方面的教程。
- 本文工具 Chrome 插件:下载地址
- Auto Alt Text Lambda API:Github repository 地址
发布于掘金 https://juejin.im/post/59a51e91f265da2499603c8c