机器之魂:聊天机器人是怎么工作的
自早期的工业时代以来,人类就被能自主操作的设备迷住了。因为,它们代表了科技的“人化”。
而在今天,各种软件也在逐渐变得人性化。其中变化最明显的当属“聊天机器人”。
但是这些“机械”是如何运作的呢?首先,让我们回溯过去,探寻一种原始,但相似的技术。
音乐盒是如何工作的

早期自动化的样例 —— 机械音乐盒。 一组经过调音的金属齿排列成梳状结构,置于一个有针的圆柱边上。每根针都以一个特定的时间对应着一个音符。
当机械转动时,它便会在预定好的时间通过单个或者多个针的拨动来产生乐曲。如果要播放不同的歌,你得换不同的圆柱桶(假设不同的乐曲对应的特定音符是一样的)。
除了发出音符之外,圆筒的转动还可以附加一些其它的动作,例如移动小雕像等。不管怎样,这个音乐盒的基本机械结构是不会变的。
聊天机器人是如何工作的
输入的文本将经过一种名为“分类器”的函数处理,这种分类器会将一个输入的句子和一种“意图”(聊天的目的)联系起来,然后针对这种“意图”产生回应。
你可以将分类器看成是将一段数据(一句话)分入几个分类中的一种(即某种意图)的一种方式。输入一句话“how are you?”,将被分类成一种意图,然后将其与一种回应(例如“I’m good”或者更好的“I am well”)联系起来。
我们在基础科学中早学习了分类:黑猩猩属于“哺乳动物”类,蓝鸟属于“鸟”类,地球属于“行星”等等。
一般来说,文本分类有 3 种不同的方法。可以将它们看做是为了一些特定目的制造的软件机械,就如同音乐盒的圆筒一样。
聊天机器人的文本分类方法
- 模式匹配
- 算法
- 神经网络
无论你使用哪种分类器,最终的结果一定是给出一个回应。音乐盒可以利用一些机械机构的联系来完成一些额外的“动作”,聊天机器人也如此。回应中可以使用一些额外的信息(例如天气、体育比赛比分、网络搜索等等),但是这些信息并不是聊天机器人的组成部分,它们仅仅是一些额外的代码。也可以根据句子中的某些特定“词性”来产生回应(例如某个专有名词)。此外,符合意图的回应也可以使用逻辑条件来判断对话的“状态”,以提供一些不同的回应,这也可以通过随机选择实现(好让对话更加“自然”)。
模式匹配
早期的聊天机器人通过模式匹配来进行文本分类以及产生回应。这种方法常常被称为“暴力法”,因为系统的作者需要为某个回应详细描述所有模式。
这些模式的标准结构是“AIML”(人工智能标记语言)。这个名词里用了“人工智能”作为修饰词,但是它们完全不是一码事。
下面是一个简单的模式匹配定义:
1 | <aiml version = "1.0.1" encoding = "UTF-8"?> |
然后机器经过处理会回答:
Human: Do you know who Albert Einstein is
Robot: Albert Einstein was a German physicist.它之所以知道别人问的是哪个物理学家,只是靠着与他或者她名字相关联的模式匹配。同样的,它靠着创作者预设的模式可以对任何意图进行回应。在给予它成千上万种模式之后,你终将能看到一个“类人”的聊天机器人出现。
2000 年的时候,John Denning 和他的同事就以这种方法做了个聊天机器人(相关新闻),并通过了“图灵测试”。它设计的目标是模仿来自乌克兰的一个 13 岁的男孩,这孩子的英语水平很蹩脚。我在 2015 年的时候和 John 见过面,他没有矢口否认这个自动机的内部原理。因此,这个聊天机器人很可能就是用“暴力”的方法进行模式匹配。但它也证明了一点:在足够大的模式匹配定义的支持下,可以让大部分对话都贴近“自然”的程度。同时也符合了图灵(Alan Turing)的断言:制作用来糊弄人类的机器是“毫无意义”的。
使用这种方法做机器人的典型案例还有 PandoraBots,他们宣称已经用他们的框架构建了超过 28.5 万个聊天机器人。
算法
暴力穷举法做自动机让人望而却步:对于每个输入都得有可用的模式来匹配其回应。人们由“老鼠洞”得到灵感,创建了模式的层级结构。
我们可以使用算法这种方法来减少分类器以便对机器进行管理,或者也可以说我们为它创建一个方程。这种方法是计算机科学家们称为“简化”的方法:问题需要缩减,那么解决问题的方法就是将其简化。
有一种叫做“朴素贝叶斯多项式模型”的经典文本分类算法,你可以在这儿或者别的地方学习它。下面是它的公式:
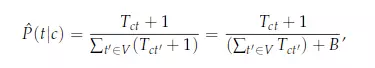
实际用起它来比看上去要简单的多。给定一组句子,每个句子对应一个分类;接着输入一个新的句子,我们可以通过计算这个句子的单词在各个分类中的词频,找出各个分类的共性,并给每个分类一个分值(找出共性这点是很重要的:例如匹配到单词“cheese”(奶酪)比匹配到单词“it”要有意义的多)。最后,得到最高分值的分类很可能就是输入句子的同类。当然以上的说法是经过简化的,例如你还得先找到每个单词的词干才行。不过,现在你应该对这种算法已经有了基本的概念。
下面是一个简单的训练集:
class: weather
"is it nice outside?"
"how is it outside?"
"is the weather nice?"
class: greeting
"how are you?"
"hello there"
"how is it going?"让我们来对几个简单的输入句子进行分类:
input: "Hi there"
term: "hi" (**no matches)**
term: "there" **(class: greeting)**
classification: **greeting **(score=1)
input: "What’s it like outside?"
term: "it" **(class: weather (2), greeting)**
term: "outside **(class: weather (2) )**
classification: **weather **(score=4)请注意,“What’s it like outside”在分类时找到了另一个分类的单词,但是正确的分类给了单词较高的分值。通过算法公式,我们可以为句子计算匹配每个分类对应的词频,因此不需要去标明所有的模式。
这种分类器通过标定分类分值(计算词频)的方法给出最匹配语句的分类,但是它仍然有局限性。分值与概率不同,它仅仅能告诉我们句子的意图最有可能是哪个分类,而不能告诉我们它的所有匹配分类的可能性。因此,很难去给出一个阈值来判定是接受这个得分结果还是不接受这个结果。这种类型的算法给出的最高分仅仅能作为判断相关性的基础,它本质上作为分类器的效果还是比较差的。此外,这个算法不能接受 is not 类型的句子,因为它仅仅计算了 it 可能是什么。也就是说这种方法不适合做为包含 not 的否定句的分类。
有许多的聊天机器人框架都是用这种方法来判断意图分类。而且大多数都是针对训练集进行词频计算,这种“幼稚”的方法有时还意外的有效。
神经网络
人工神经网络发明于 20 世纪 40 年代,它通过迭代计算训练数据得到连接的加权值(“突触”),然后用于对输入数据进行分类。通过一次次使用训练数据计算改变加权值以使得神经网络的输出得到更高的“准确率”(低错误率)。
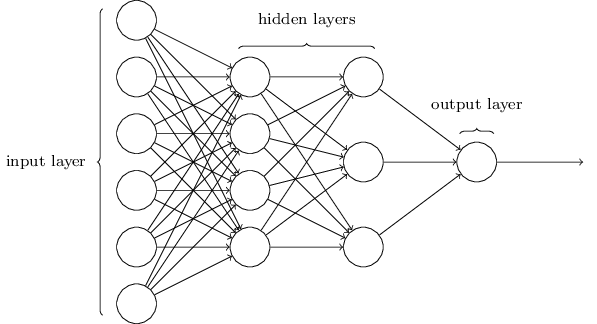
上图为一种神经网络结构,其中包括神经元(圆)和突触(线)
其实除了当今的软件可以用更快的处理器、更大的内存外,这些结构并没有出现什么新奇的东西。当做数十万次的矩阵乘法(神经网络中的基本数学运算)的时候,运行内存和计算速度成为了关键问题。
在前面的方法里,每个分类都会给定一些例句。接着,根据词干进行分句,将所有单词作为神经网络的输入。然后遍历数据,进行成千上万次迭代计算,每次迭代都通过改变突触权重来得到更高的准确率。接着反过来通过对训练集输出值和神经网络计算结果的对比,对各层重新进行计算权重(反向传播)。这个“权重”可以类比成神经突触想记住某个东西的“力度”,你能记住某个东西是因为你曾多次见过它,在每次见到它的时候这个“权重”都会轻微地上升。
有时,在权重调整到某个程度后反而会使得结果逐渐变差,这种情况称为“过拟合”,在出现过拟合的情况下继续进行训练,反而会适得其反。
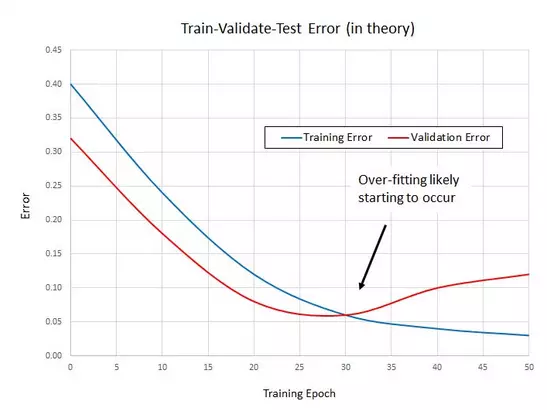
训练好的神经网络模型的代码量其实很小,不过它需要一个很大的潜在权重矩阵。举个相对较小的样例,它的训练句子包括了 150 个单词、30 种分类,这可能产生一个 150x30 大小的矩阵;你可以想象一下,为了降低错误率,这么大的一个矩阵需要反复的进行 10 万次矩阵乘法。这也是为什么说需要高性能处理器的原因。
神经网络之所以能够做到既复杂又稀疏,归结于矩阵乘法和一种缩小值至 -1,1 区间的公式(即激活函数,这里指的是 Sigmoid),一个中学生也能在几小时内学会它。其实真正困难的工作是清洗训练数据。
就像前面的模式匹配和算法匹配一样,神经网络也有各种各样的变体,有一些变体会十分复杂。不过它的基本原理是相同的,做的主要工作也都是进行分类。
机械音乐盒并不了解乐理,同样的,聊天机器人并不了解语言。
聊天机器人实质上就是寻找短语集合中的模式,每个短语还能再分割成单个单词。在聊天机器人内部,除了它们存在的模式以及训练数据之外的单词其实并没有意义。为这样的“机器人”贴上“人工智能”的标签其实也很糟糕。
总结:聊天机器人就像机械音乐盒一样:它就是一个根据模式来进行输出的机器,只不过它不用圆筒和针,而是使用软件代码和数学原理。
发布于掘金 https://juejin.im/post/599155d86fb9a03c467c151d