事件抽取技术发展现状简述
问题定义
事件抽取(Event Extraction)是一种面向非结构化文本或半结构化数据的信息抽取(Information Extraction)任务,与传统面向知识图谱的实体、关系、属性等信息抽取有所不同的是,事件抽取抽取的是"事件",即某些事物在时空范围内的运动。在 ACE(Automatic Content Extraction)测评会议中,事件被描述成: "在特定时间内,发生的,同时有参与者的,存在状态变化的事情。例如,"李主任将在明天举办的大会上发言"中描述了具体的事件,这样的句子也被称为事件提及,包含了"李主任"-"大会"-"发言"这些事件要素。而事件抽取的目的,正是从非结构化、半结构化的事件提及中将结构化的事件要素提取出来从而进行分析。事件抽取是不少任务的前置模块,对于事理图谱构建、情报分析、新闻摘要、自动问答等任务均有着重要的作用,事件抽取的准确程度也会显著地影响后续任务的效果。
一般来说,根据是否有明确的、事先定义好的事件模式(或事理图谱 schema),可以将事件抽取分为封闭域事件抽取(Close-domain Information Extraction,也有称为限定域事件抽取)与开放域事件抽取(Open-domain Information Extraction)。封闭域事件抽取的主要任务包括:
- 触发词检测:触发词(Trigger)是事件抽取中的重要信息,一般是出现在事件提及中,最能明确表达发生事件的词,一般是动词或名词。例如,"20年前的春天,他出生了"一句中,"出生"为该事件提及文本中的事件触发词。
- 事件类型检测:即通过分类等方式得到事件的类型,由于触发词在事件中的关键性,因此也可以被视作触发词类型检测。事件的类型取决于事件模式的设计,或事理图谱schema的设计。例如,某事件模式中将"咬伤"、"砍死"等触发词的事件定义为"伤害"类型的事件。
- 事件论元抽取:事件论元(Event Argument)指的是事件中的参与者,包含实体、时间、数值、文本等数据组成。例如,"张三在2022年成功晋升"中的张三、2022年均为"晋升"事件的事件论元。
- 论元角色识别:根据事件模式或事理图谱的定义,将抽取的事件论元按照其在事件中扮演的具体角色进行分类。例如,在某"公安事理图谱"中的"张三"、"李四"等人在其对应的犯罪记录中均为"加害者"这一事件角色。
根据上述不同事件抽取任务得到的数据,可以明确地描述一个具体的事件。一个完整的封闭域事件抽取系统,应当以联合模型(Joint Model)或抽取流水线(Pipeline)的形式得到上述的内容,或者至少得到触发词、论元。以一个具体的例子展示封闭域事件抽取:"詹姆斯枪击了弗兰克"中,包含攻击类型的事件,其触发词为枪击,事件论元包含詹姆斯和弗兰克,前者的论元角色是攻击者,后者的论元角色是被攻击者。
而开放域事件抽取与封闭式事件抽取不同,没有明确的事件模式或 schema,因此构建开放域事件抽取不拘泥于精确地将事件具体要素进行精确抽取,其主要目的一般是通过聚类、文本语义分割等无监督手段,在开放的文本数据中分析、检测出事件,以供后续的分析。开放域事件抽取在舆情感知、舆情分析、情报分析、股市情绪调研等应用中有着重要的作用。开放域事件抽取的主流任务基本可分为:
- 事件分割:也有称故事分割,给定一段文本(如新闻、论坛发言等),检测出不同事件的边界。例如,在央视"今日新闻简讯"中包含了当日多条要闻,有的新闻条目使用了多段文本描述,有的文本段落中一次包含了多条新闻,将它们分离成独立的事件文本片段即为本任务的目标。
- 事件发现:在新闻、论坛发言等文本中,检测出新的事件(New Event Detection)。常用于舆情系统等应用。
- 事件追踪:在新闻、论坛发言等文本中,检测同属于之前的已有事件的文本片段,通过此方式追踪事件(Event Tracking)的发展情况。常用于舆情系统等应用。
由于开放域事件抽取并没有像 ACE 那样公认、权威的任务范式,因此上述分类可能根据实际应用场景、数据集等条件产生变动。但一般来说,开放域事件抽取的粒度较粗,一般不会对具体的触发词类型、论元角色层面的信息进行抽取。
本文中主要对封闭域事件抽取进行简述。
评价指标
事件抽取的评价指标主要为 P、R、F1。其中P为准确率(Precision),P=正确抽取结果数/抽取结果总数,R为召回率(Recall),R=正确抽取结果数/需抽取结果总数,F1=P*R/(P+R)。对于自动抽取系统或将事件抽取作为信息处理流水线的一部分时,应尽量提高F1指标,以降低抽取错误造成后续步骤的错误累积;在有人工干预的事件抽取系统中,应在保证一定F1指标的基础上,尽量提升召回率指标,以尽量确保抽取时不漏抽。
在评测事件抽取模型或系统时,一般使用上述指标分别对事件模式中的各部分子任务分别进行评价,例如在相关论文中一般会同时汇报 TI(Trigger Identification,触发词识别)、TC(Trigger Classification,触发词分类,即事件类型分类)、AI(Argument Identification,论元识别)、AC(Argument Classification,论元分类,即论元角色分类)四个子任务的 P、R、F。
基准数据集
ACE05 是事件抽取任务最常用的基准数据集,包含了英语、阿拉伯语和汉语的精标注信息抽取数据,囊括了事件抽取中几个最常见的子任务。ACE05 遵循 LDC(Linguistic Data Consortium)的用户协议,需要注册为LDC会员才能下载与使用。
对于特定的事件抽取任务也会有相关数据集,例如针对舆情分析、公关、政治事件检测的CrisisLexT26、BlackLivesMatterU、SoSItalyT4 等社交网络数据集,针对突发事件、自然灾害的ChileEarthquakeT1等数据集均可以作为事件抽取数据集在特定任务上使用。
对于特定语言(尤其是中文)的事件抽取任务,除了 ACE05 之外,比较知名的还有上海大学构建的CEC 中文突发事件语料库、CEEC 中文环境突发事件语料库、百度DuEE数据集等。
除了上述数据集外,还有KBP数据集(TAC Knowledge Base Population)等知识图谱相关数据集也提供了事件抽取任务相关的标注。另外部分开源项目、信息抽取竞赛也会提供对应的事件抽取数据集,然而相较于其它信息抽取任务,事件抽取的基准数据集,尤其是中文语种的基准数据集依然稀缺,这也促使了少样本(few-shot)事件抽取、基于远程监督(Distantly Supervised)等事件抽取等方法的发展。
常用方法与典型技术
事件抽取任务早在 20 世纪 50 年代便有研究者开始研究,传统的事件抽取方法一般以相关领域专家手工编写规则、指定模板匹配等方式实现。随着网络信息的爆炸式增加,传统的方法开始无法胜任新的需求,基于统计的机器学习方法、深度学习模型等新的技术应运而生,大幅提高了事件抽取任务的效果。本节将介绍上述几种方法的典型代表。
而近年来,还出现了利用外部知识(如背景知识、知识图谱)增强事件抽取效果的工作,以及少样本事件抽取的新任务范式,基于问答的事件抽取新模型,以及针对特定数据(如日志数据、生物数据等)事件抽取的相关工作,将在后续发展趋势章节中介绍。
基于模式匹配的事件抽取
基于模式匹配的事件抽取方法一般需要领域专家人工构建规则与模板,这些规则与模板通常会以词典、正则、语法树等形式进行匹配。典型的事件抽取专家系统(如 AutoSlog、PALKA)以及后续使用部分统计或学习方法来改善规则的系统(如 CRYSTAL、AutoSlog-ST 等)都是基于这种形式实现的抽取。
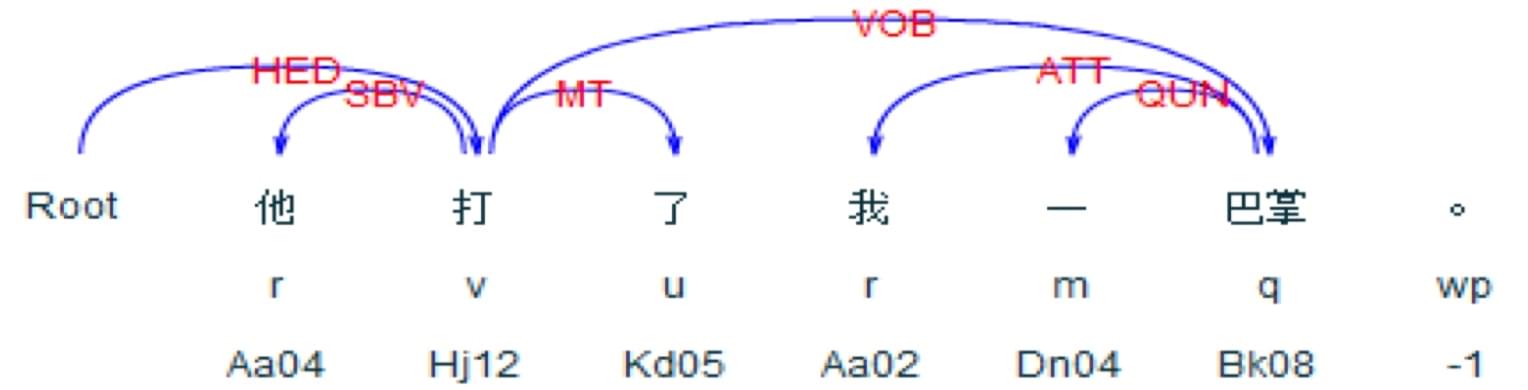
上图为一个典型的模式匹配规则(SBV-VOB),当句子中仅含有单个主语和宾语,且谓语不是系动词或助动词时,则谓语动词一般是触发词。 这类基于模式匹配的方法通常包含构建与抽取两个步骤,即事先在语料上发掘出规则,然后将规则应用到新的待抽取文本上进行匹配。如下图所示:
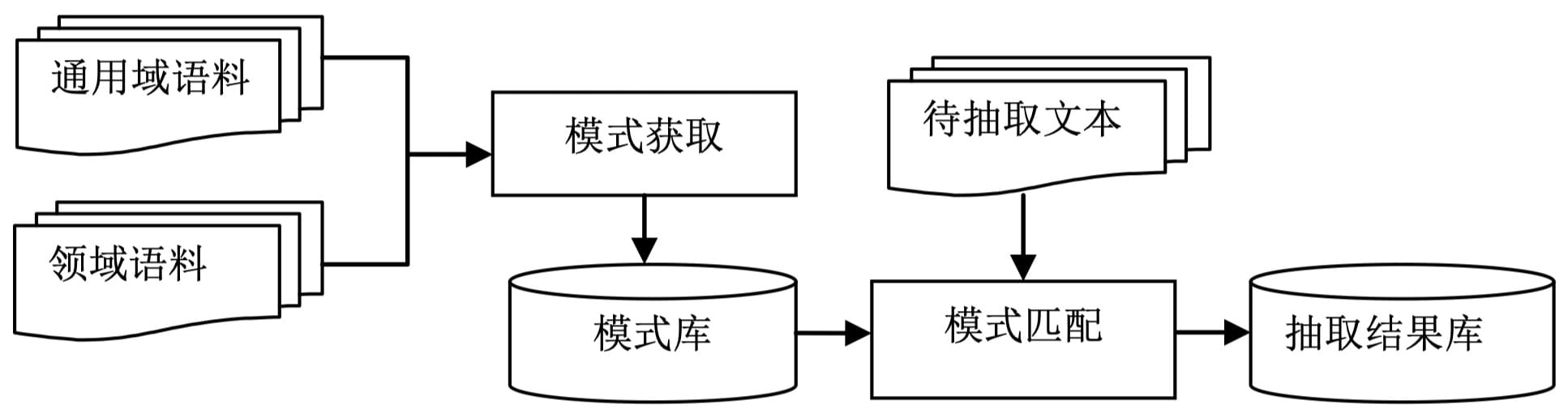
基于模式匹配的事件抽取方法虽然时间久远且限制较多,但它有着很好的可解释性,以及对精标注数据的数据量要求不高,即使在近期也有相关研究在推进,如 GenPAM 等系统。相比于经典的专家系统,这些较新的系统有一定的能力自动从通用语料和领域语料中自动挖掘或生成对应的模式,在一定程度上可以降低人力成本。但一般来说此类方法的准确率依然受限。
基于机器学习技术的事件抽取
由于基于模式匹配的方法通常需要大量人力资源,且效果不佳,特别是在迁移到新的领域数据上时需要重新挖掘模式,因此基于统计机器学习的方法在 20 世纪后逐渐替代了传统的模式匹配方法。

上图展示了经典的机器学习事件抽取流程,其中事件装配(Event Assembling)一般是对分类结果的后处理,如事件合并、聚类等。比较典型的统计机器学习方法包括最大熵模型(Maximum Entropy Model)、支持向量机(Support Vector Machine)、条件随机场(Conditional Random Field)等,一般来说此类工作的特点是作者会精心根据数据集和模型选择特征(如POS、bigram等),并将问题视为分类问题,例如 AAAI 2002《A Maximum Entropy Approach to Information Extraction from Semi-Structured and Free Text》以"指示词"、POS、在两个指示词中间的动词等特征进行结合,送入最大熵模型进行分类以得到事件类型。
对于触发词识别、论元识别等,一般使用 CRF 等方法将问题建模为序列标注任务,如 COLING 2012《Joint Modeling of Trigger Identification and Event Type Determination in Chinese Event Extraction》利用马尔可夫随机场进行序列标注,得到了很好的效果。
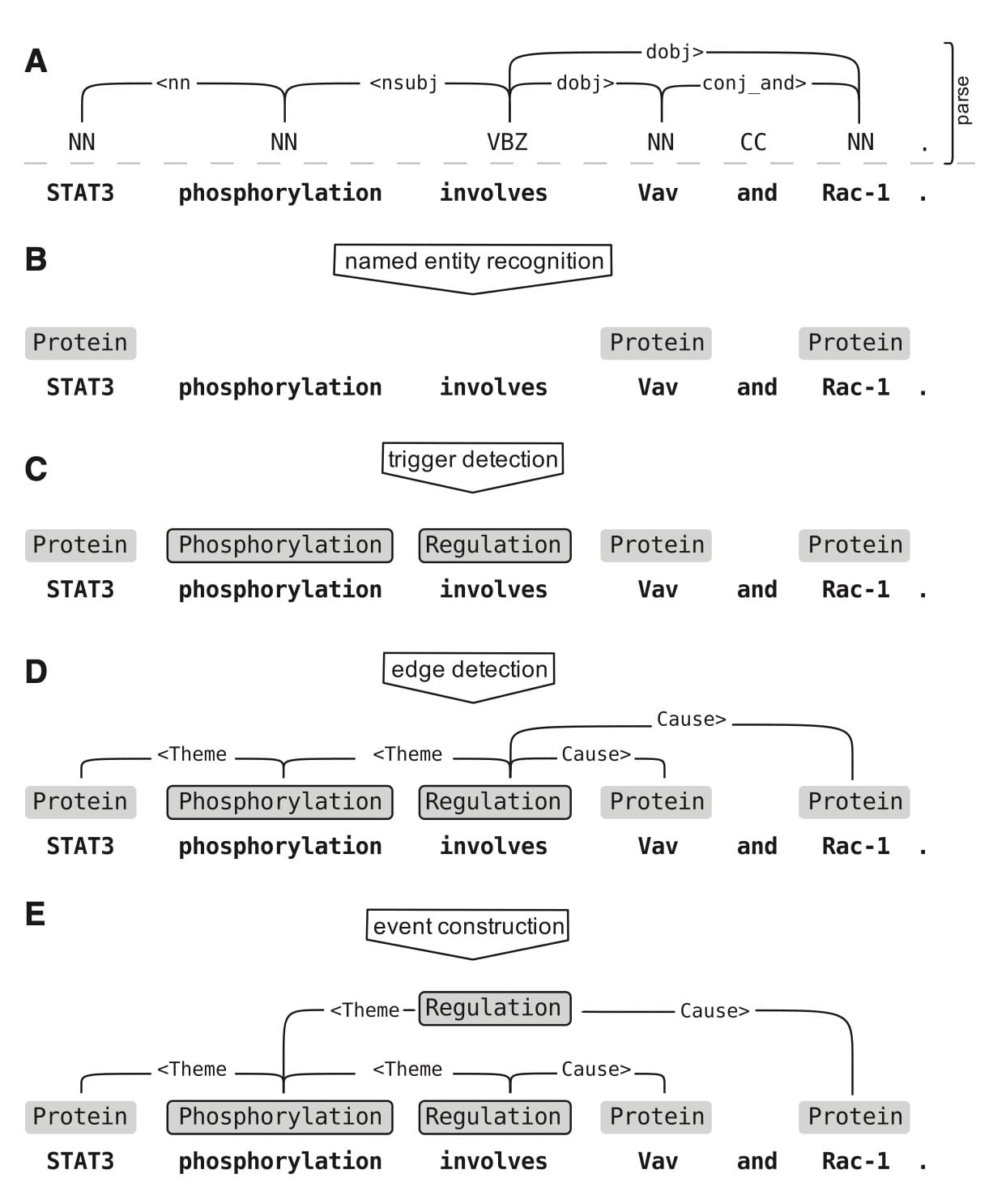
上图为经典工作《Complex event extraction at PubMed scale》的事件抽取流水线,其中步骤 A 为句法树 parse,步骤 B 为利用 CRF 和已有特征进行命名实体识别,步骤 C 为利用分类模型对每个词单独分类从而识别触发词类型,步骤 D 为在触发词和实体间使用 SVM 构造多标签分类模型进行连边检测,最后在步骤E组合成为一个事件。
如何选择或构建合适的特征,即特征工程对机器学习方法的效果有着决定性的影响;以及统计机器学习方法通常需要大规模的精标语料库,且容易收到语料类别不均衡、长尾数据等情况的影响;并且难以融入外部的先验知识,因此在近年深度学习技术高速发展的浪潮中逐渐被替代。
基于深度学习技术的事件抽取
深度学习是机器学习技术的一个分支,通过深层神经网络解决了传统机器学习方法学习能力有限,无法通过持续增加数据量提升学习到的知识总量的问题,并有一定的自动表征能力,解放了设计机器学习模型时设计与构建特征的难题。在近年来随着算力和数据的共同发展,深度学习在自然语言处理等领域得到了广泛的研究与应用,最新的事件抽取方法大都是基于深度学习模型所构建的。
基于深度学习的事件抽取模型五花八门,并随着深度学习模型的发展而提出更多、更新的方法。例如,可以与 TextCNN 一样使用卷积神经网络(CNN,Convolutional Neural Network)来提取文本的特征,然后送入分类模型进行分类,或进行序列标注;也可以利用长短记忆神经网络(LSTM,Long Short Term Memory networks)的链式网络结构对句子中各个词的上下文关系进行建模,以提升效果;亦或是使用最新的BERT等预训练语言模型,在大规模预训练的基础之上再对事件抽取任务进行微调。
例如,ACL 2015《Event Extraction via Dynamic Multi-Pooling Convolutional Neural Networks》提出了一种典型的深度学习事件抽取模型,其论元分类的模型结构如图所示:
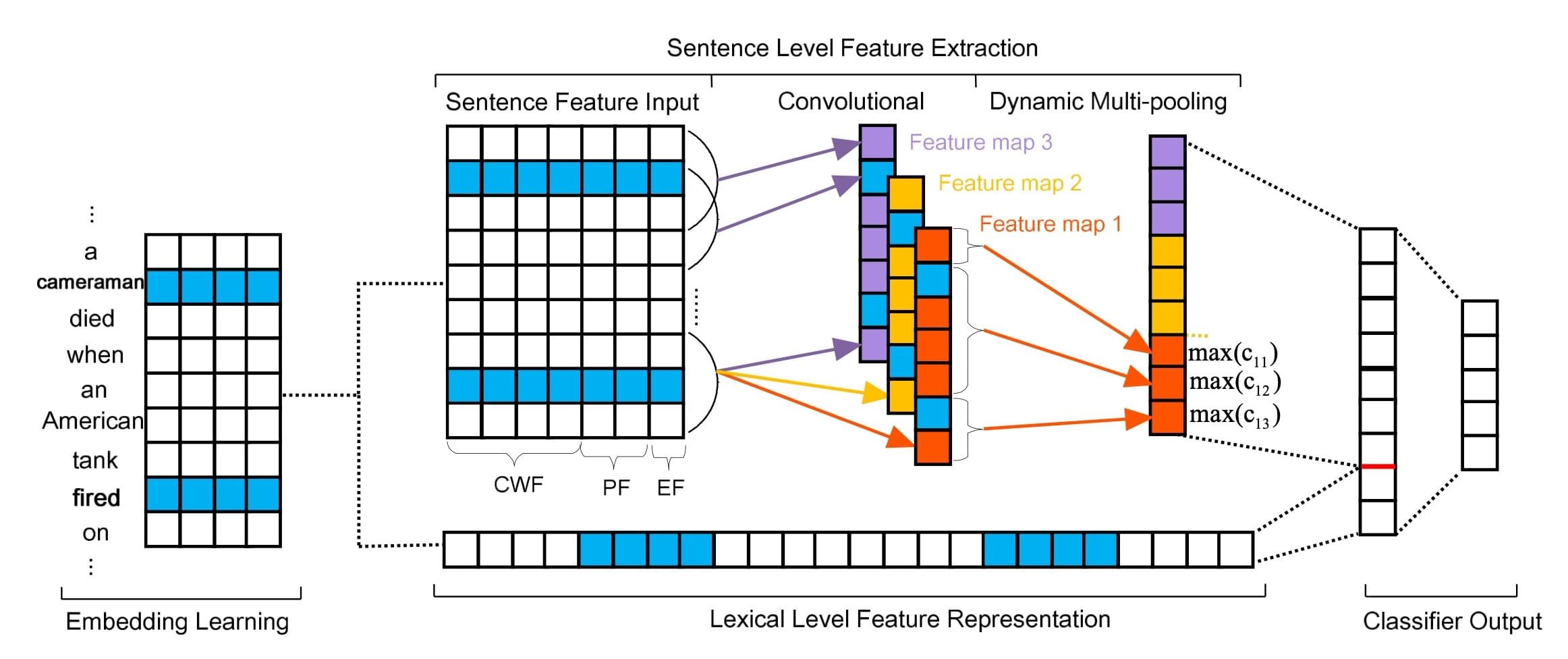
首先使用词嵌入(Word Embedding),得到词表中单词的表示向量;当输入一段文本时,将文本的实体的表示向量从词嵌入中查出,作为词汇特征表示(Lexical Level Feature Representation);然后对整个句子使用 CNN + 最大池化的方式,得到句子的特征表示(Sentence Level Feature);最后将实体的词汇表示和句子特征拼在一起,进行分类并输出。通过这样简单的建模方式,经过监督训练后,就可以在 ACE2005 数据集上达到当时最好的效果,足以体现深度学习技术的强悍。
再例如,ACL 2019《Exploring Pre-trained Language Models for Event Extraction and Generation》提出了一个两阶段的深度学习事件抽取模型,其抽取模型的结构如图所示:
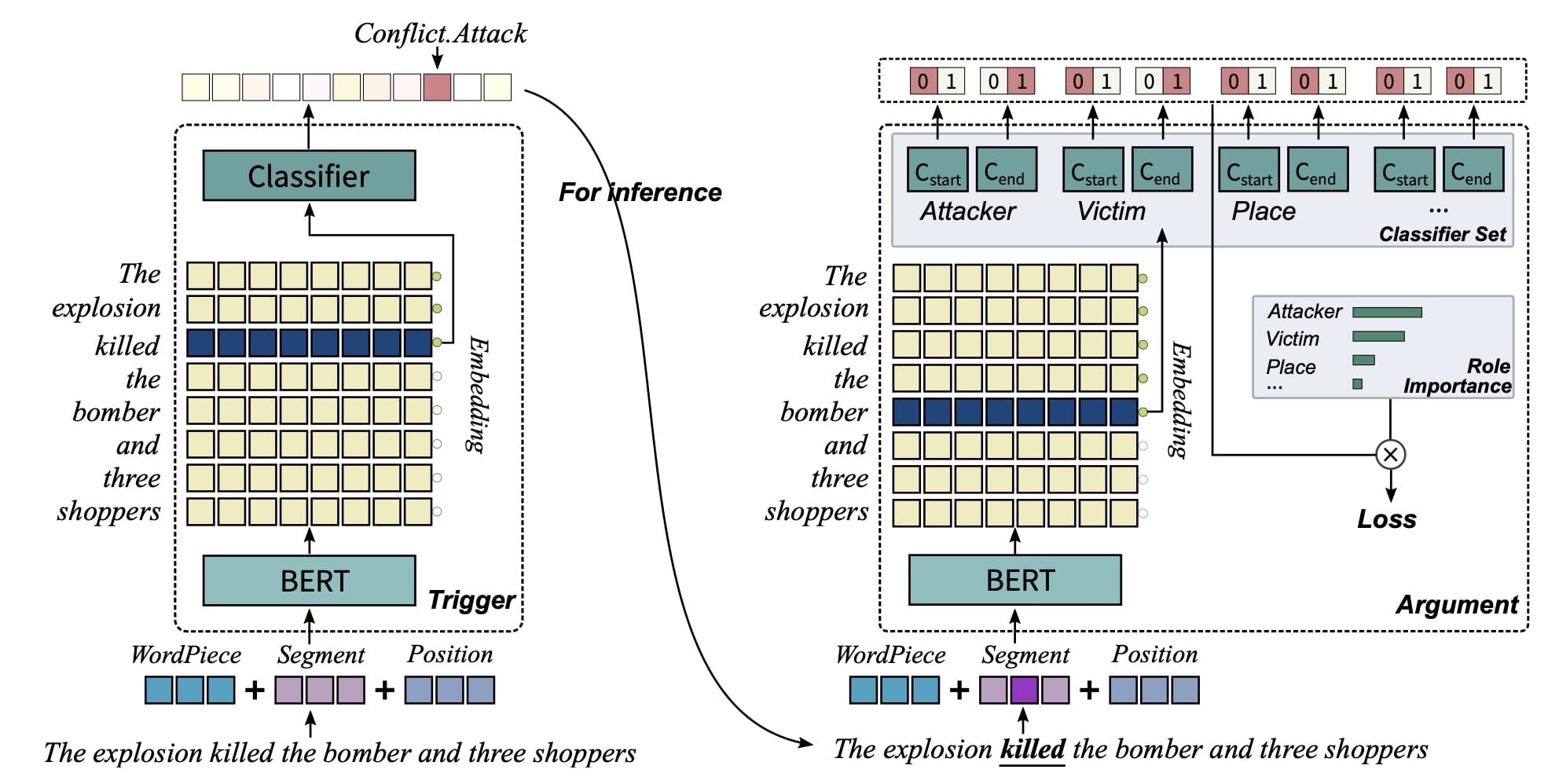
本文使用了预训练语言模型 BERT 来作为文本表示模型。文中的抽取模型分为两步:触发词抽取(左)与论元抽取(右)。首先通过 BERT 的序列标注方式,对句子中的每个词进行分类,得到各个词能作为某一类触发词的可能性;然后将各个触发词与原句字一同送入论元抽取模型中,对每个词执行二分类,即可得到单个词作为指定触发词论元的概率,通过这种方式解决了一个词同时作为多个事件的论元的重叠(overlap)问题。
除了上述基于传统深度学习方法外,还有人使用图神经网络(Graph Neural Network)的形式来建模事件抽取问题(如 AAAI 21《GATE: Graph Attention Transformer Encoder for Cross-lingual Relation and Event Extraction》),同时还有各式各样更加有趣的神经网络模型不断被应用到事件抽取任务中;在可以预见的将来,深度学习会继续统治事件抽取这一课题,并在事件抽取基准数据集上不断刷新效果。
事件抽取技术发展趋势
随着深度学习的发展,事件抽取技术越发成熟,但同时也暴露出了一些问题,如:数据集大小不足、多样性不足;小语种、低资源语种缺乏数据等。因此,近年来有研究者开始针对在数据受限的情况下,通过引入外部知识、小样本(few-shot)抽取等手段,或者利用问答技术来提升事件抽取模型的泛用性与效果。
利用外部知识增强事件抽取
为了弥补事件抽取数据集受限的实时,不少研究者尝试引入外部知识以增强事件抽取的效果。例如,ACL 2016《Leveraging FrameNet to Improve Automatic Event Detection》引入了额外的语言资源库FrameNet来自动生成符合ACE要求的带标签新数据,从而实现对ACE2005数据集的扩充,并提升模型效果;ACL 2017《Automatically Labeled Data Generation for Large Scale Event Extraction》引入 Freebase 知识库,将其中的 CVT 映射为事件类型、CVT 实例映射为事件实例、CVT 值映射为论元、CVT 角色映射为论元的角色,并通过 FrameNet 过滤噪声等。
随着知识库构建、预训练语言模型的增强,引入外部知识的手段将会更加丰富,对于增强事件抽取将会有更进一步的帮助。
小样本事件抽取范式
小样本学习(few-shot learning,或少样本学习)与传统深度学习模式有所区别,通常形式为一个非常小的支撑集(support set)提供标签信息,通过度量学习等方式让模型得到一定的泛化能力。例如,ACL 2020 NUSE worksthop《Extensively Matching for Few-shot Learning Event Detection》提出了一种用于 Event Detection 的小样本学习方法,它将任务设定为(n+1)-way k-shot,即给定一个包含 n 类的支撑集(以及一个额外的 NULL 集来标识没有事件的情况),其中每一类只有k个数据。在训练时,该文设定了损失函数:
\[ L=L_{\text {query }}+\beta \hat{L}_{\text {intra }}+\gamma \hat{L}_{\text {inter }} \]
其中 L_intra 为类内损失,即让同一个聚类的类内距离越小越好:
\[ L_{i n t r a}=\sum_{i=1}^{N} \sum_{k=1}^{K} \sum_{j=k+1}^{K} \operatorname{mse}\left(v_{i}^{j}, v_{i}^{k}\right) \]
L_inter 为类间损失,让不同聚类距离(即类心原型距离)越远越好:
\[ L_{i n t e r}=1-\sum_{i=1}^{N} \sum_{j=i+1}^{N} \operatorname{cosine}\left(c_{i}, c_{j}\right) \]
L_query 为query 损失,让 query 能尽量与正确对应的原型距离更近:
\[ \begin{gathered} L_{q u e r y}(x, S)=-\log P(y=t \mid x, S) \\ P\left(y=t_{i} \mid x, S\right)=\frac{\exp \left(-d\left(f(q, p), \mathbf{c}^{i}\right)\right)}{\sum_{j=1}^{N} \exp \left(-d\left(f(q, p), \mathbf{c}^{j}\right)\right)} \end{gathered} \]
经过对L的训练后,模型在 5-way 5-shot 和 10-way 10-shot 的设定上得到了良好的效果。
除了这篇文章之外,还有不少的研究者也在研究如何用少量的数据来训练好一个事件抽取模型,甚至不用数据(zero-shot)通过迁移学习等手段来让模型有良好的效果。随着小样本学习、元学习等深度学习技术的进步,小样本事件抽取也将由此收益,从而有更好的效果与更广阔的应用前景。
基于问答的事件抽取
针对传统深度学习事件抽取模型无法对标签中的语义进行建模、无法捕获标签到触发词或论元的交互、泛化能力低的问题,研究者们提出了利用问答的形式来增强事件抽取的效果,近年来这种方案有多篇顶会论文进行研究。
较为典型的是 EMNLP 2020《Event Extraction as Multi-turn Question Answering》,将事件抽取问题以下图所示的问答的形式向机器提出:

该文使用了一种多轮问答的框架用于解决事件抽取,可以充分利用触发词、事件类型和论元之间的交互信息,同时利用多轮问答策略以捕捉相同事件类型中不同论元角色之间的依赖。其模型框架图如下所示:
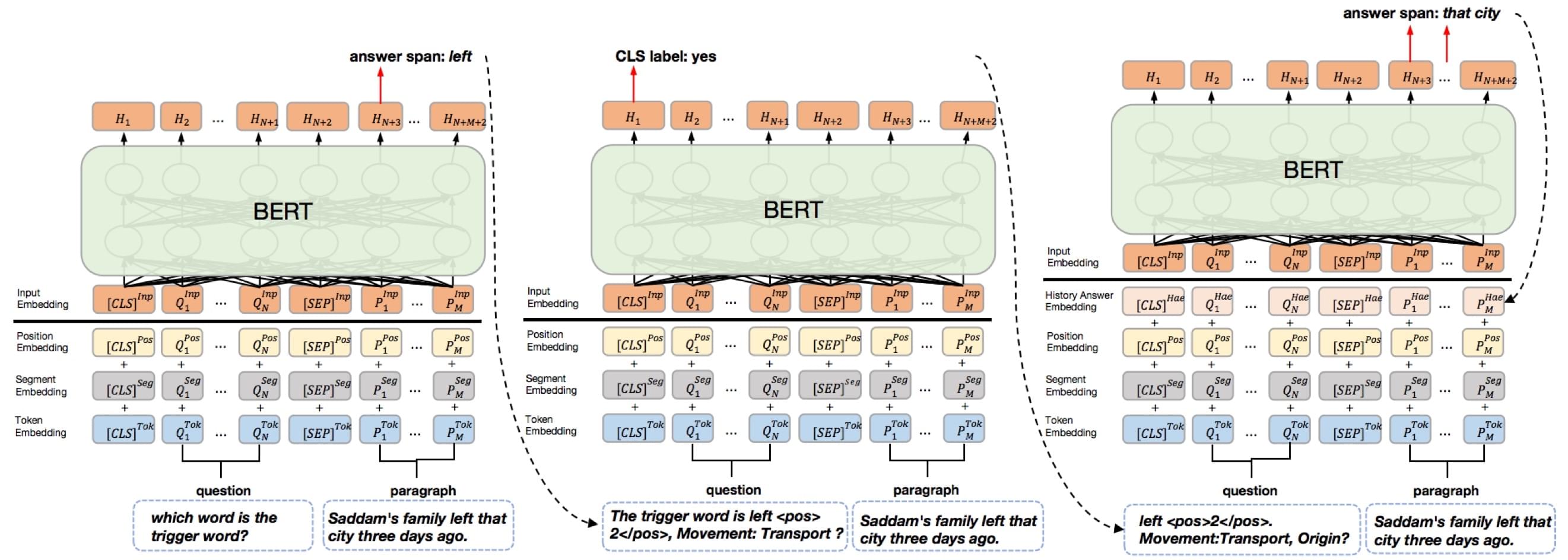
左边为触发词识别,利用机器阅读理解(MRC,Machine Reading
Comprehension)的形式,通过提问从文本中取出触发词;得到触发词后,将其作为提示语,送入中间的触发词分类模型进行分类,同样是提出问题(问题定义为
The trigger word is
面向特定数据的事件抽取
除了传统自然语言处理问题外,还有其它领域的应用可以从事件抽取技术中获益。例如,针对分布式系统产生的海量日志进行事件抽取,可以从中构建错误事理图谱,或者从中挖掘不同节点的错误依存关系等模式。在日志分析系统中的部分模块,例如日志 segmentation(切分)与 parsing,也可以从开放域事件抽取的事件分割等技术得到启发,更加精确地对不同节点产生的日志进行划分。日志事件抽取样例如下图所示:

例如,ISC 2018《Event Extraction from Streaming System Logs》提出了在流系统日志上执行事件抽取,通过一定的领域知识(例如IP地址的格式、日志日期等可以使用正则表示),及模板匹配等手段,可以得到对应的日志事件的结构化信息。
除了用在日志数据上外,事件抽取技术也可以用在各类生物、医学等领域的数据上,事件抽取技术的发展不仅利于自然语言处理领域,也能惠及其它学科的信息化进程。
Reference
- [1] ACE2005 Dataset: http://projects.ldc.upenn.edu/ace/
- [2] Chen et al, Event extraction via dynamic multi-pooling convolutional neural networks, ACL 2015
- [3]项威 王邦, 中文事件抽取综述, 计算机技术与发展 2020, 卷2
- [4] Björne et al, Complex event extraction at PubMed scale, Bioinformatics (2010), 26
- [5] Yang et al, Exploring pre-trained language models for event extraction and generation, ACL 2019
- [6] Li et al, Event Extraction as Multi-turn Question Answering, EMNLP 2020
- [7] Sheng et al, Casee: A joint learning framework with cascade decoding for overlapping event extraction, ACL 2021
- [8] Liu et al, An overview of event extraction and its applications, arxiv 2021