Open Domain Question Answering Using Early Fusion of Knowledge Bases and Text 论文笔记
此论文《Open Domain Question Answering Using Early Fusion of Knowledge Bases and Text》发表于 EMNLP 2018。
对于开放域问答问题,作者试图将与问题有关的 Wikipedia 和 Freebase 的知识结合起来构成一个融合子图,然后把开放域问答问题转换为在这个融合子图上的节点分类问题,是一篇典型的早期融合的工作。如下图的左右两部分所示,该文章要点有两处:(1)如何对知识库和文本进行联合构图;(2)如何在图上执行节点分类获得问题的答案。
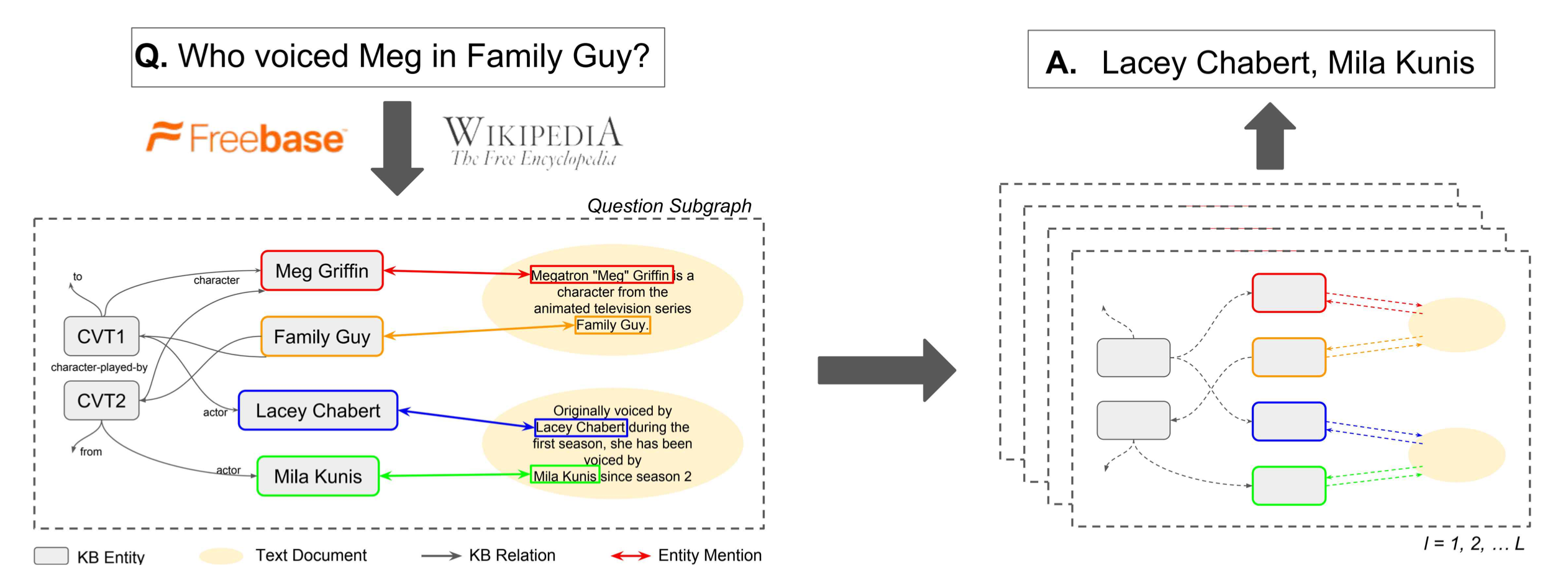
融合子图的构建
将整个Wikipedia与Freebase进行联合构图是不现实的,因此作者先分别在知识库找出与问题相关的部分,然后通过不断在文本库中检索文本相关文本,加入融合子图中。
(1)从知识库构建问题相关子图:首先通过实体链指从问题\(q\)中获取一系列种子实体\(S_q\),然后以这些种子实体为起点,执行Personal PageRank(PPR)算法,根据PPR得到的权重找出与种子实体相连的Top-E候选实体\(v_{1}, \ldots, v_{E}\),将种子实体、候选实体和他们间的连边合起来,构成子图\(\mathcal{G}_q = \left(\mathcal{V}_{q}, \mathcal{E}_{q}, \mathcal{R}\right)\),其中\(\mathcal{V}\)为节点,\(\mathcal{E}\)为连边,\(\mathcal{R}\)为边的类型(即关系类型)。
(2)文本信息节点:首先通过DrQA的带权词袋模型对文本库进行句子级别的检索,得到Top5与问题相关的文档,然后根据问题\(q\)与文档中的句子进行检索排序,找出最相关的Top-D个候选句子\(d_{1}, \ldots d_{D}\)。将这Top-D个句子依次加入问题相关子图\(\mathcal{G}_q\)中: \[ \mathcal{V}_{q}=\left\{v_{1}, \ldots, v_{E}\right\} \cup\left\{d_{1}, \ldots, d_{D}\right\} \] 对于节点的连边,以如下的形式进行连接: \[ \mathcal{E}_{q}=\left\{(s, o, r) \in \mathcal{E}: s, o \in \mathcal{V}_{q}, r \in \mathcal{R}\right\} \cup\left\{\left(v, d_{p}, r_{L}\right):\left(v, d_{p}\right) \in \mathcal{L}_{d}, d \in \mathcal{V}_{q}\right\} \]
其中\(r_L\)表示从文档句子到实体的连边关系。即,将句子和图\(\mathcal{G}_q\)中已有的实体添加连边。由此,得到了包含知识库信息和文本信息的融合子图\(\left(\mathcal{V}_{q}, \mathcal{E}_{q}, \mathcal{R}^{+}\right)\),\(\mathcal{R}^{+}=\mathcal{R} \cup\left\{r_{L}\right\}\)。
图表示学习与节点分类
在上一步中,已经获得了包含知识库节点、文档节点、文档到实体连边的与问题\(q\)相关的异构融合子图\(\mathcal{G}_q\)。此工作先采用图表示学习的方法得到各个节点的表示,然后对各个节点是否属于答案进行二分类训练。该方法命名为GRAFT-Net,分为两步:
(1)初始化节点表示:对于知识库中的实体节点,赋予定长表示向量:\(h_{v}^{(0)}=x_{v} \in \mathbb{R}^{n}\),其中\(x_v\)可以是随机向量也可以是通过TransE等方式预训练得到表示向量。对于文本的文档节点,如果文档是由单词\(w_{1}, \ldots, w_{|d|}\)构成的,则使用LSTM对词嵌入进行编码\(H_{d}^{(0)}=\operatorname{LSTM}\left(w_{1}, w_{2}, \ldots\right)\)。
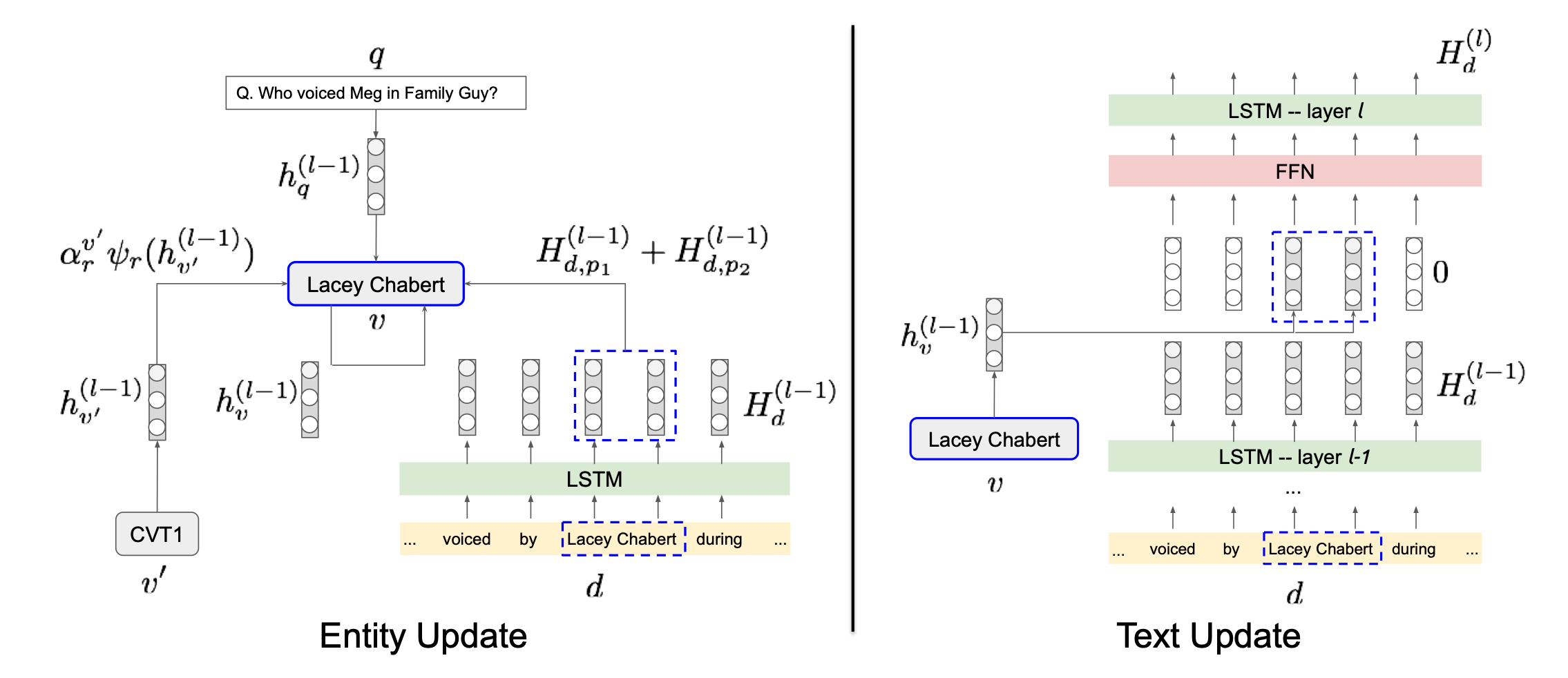
(2)异构融合子图的更新:由于前一步得到的图是异构的,需要根据问题\(q\)分别对实体节点与文档节点进行更新,如上图所示。对于实体节点\(v\),每一层GRAFT-Net执行如下更新: \[ h_{v}^{(l)}=\mathrm{FFN}\left(\left[\begin{array}{c} h_{v}^{(l-1)} \\ h_{q}^{(l-1)} \\ \sum_{r} \sum_{v^{\prime} \in N_{r}(v)} \alpha_{r}^{v^{\prime}} \psi_{r}\left(h_{v^{\prime}}^{(l-1)}\right) \\ \sum_{(d, p) \in M(v)} H_{d, p}^{(l-1)} \end{array}\right]\right) \] 其中\(h_{v}^{(l-1)}\)是上一层该节点的表示,\(h_{q}^{(l-1)}\)是上一层的问题表示,\(\sum_{r} \sum_{v^{\prime} \in N_{r}(v)} \alpha_{r}^{v^{\prime}} \psi_{r}\left(h_{v^{\prime}}^{(l-1)}\right)\)中的\(N_{r}(v)\)是节点\(v\)的邻居实体节点,\(\psi_{r}\left(h_{v^{\prime}}^{(l-1)}\right)\)是根据PageRank的权重控制连边上的权重传递(propagation),\(\alpha_{r}^{v^{\prime}}\)是在关系\(r\)上执行注意力机制加权,以权衡问题节点对实体节点的影响;\(\sum_{(d, p) \in M(v)} H_{d, p}^{(l-1)}\)中的\(M(v)\)是与节点\(v\)相邻的文档节点,\(H_{d, p}^{(l-1)}\)是实体在文本中的表示。 而文档节点的表示,是由一系列单词的表示再通过LSTM进行编码得到的,因此文档节点表示的更新本质上是文档中单词表示的更新。假如文档\(d\)中位置\(p\)上的单词与实体节点相连,将这些实体节点记为\(L(d, p)\),该单词的表示更新如下所示: \[ \tilde{H}_{d, p}^{(l)}=\operatorname{FFN}\left(H_{d, p}^{(l-1)}, \sum_{v \in L(d, p)} h_{v}^{(l-1)}\right) \] 实质上就是对邻接实体节点进行了聚合。最后,文档节点也会更新:\(H_{d}^{(l)}=\operatorname{LSTM}\left(\tilde{H}_{d}^{(l)}\right)\)。
在问题节点的引导下,GRAFT-Net会以类似PageRank的形式,将问题节点的表示向整个异构融合子图中传播,最终得到融合了问题表示、实体表示、文本表示的异构融合子图中每个节点的表示\(h_{v}^{(L)} \in \mathbb{R}^{n}\)。只需要对它进行二分类训练: \[ \sigma\left(w^{T} h_{v}^{(L)}+b\right) \] 就能分出融合子图中与问题相关的节点了,即得到了问题的答案。