Question Answering with Subgraph Embeddings 论文笔记
《Question Answering with Subgraph Embeddings》发表于 2014 年的 EMNLP,提出了一种基于对问题嵌入与候选子图嵌入进行打分的排序学习的方法,是基于信息检索的知识库问答中比较有代表性的工作。
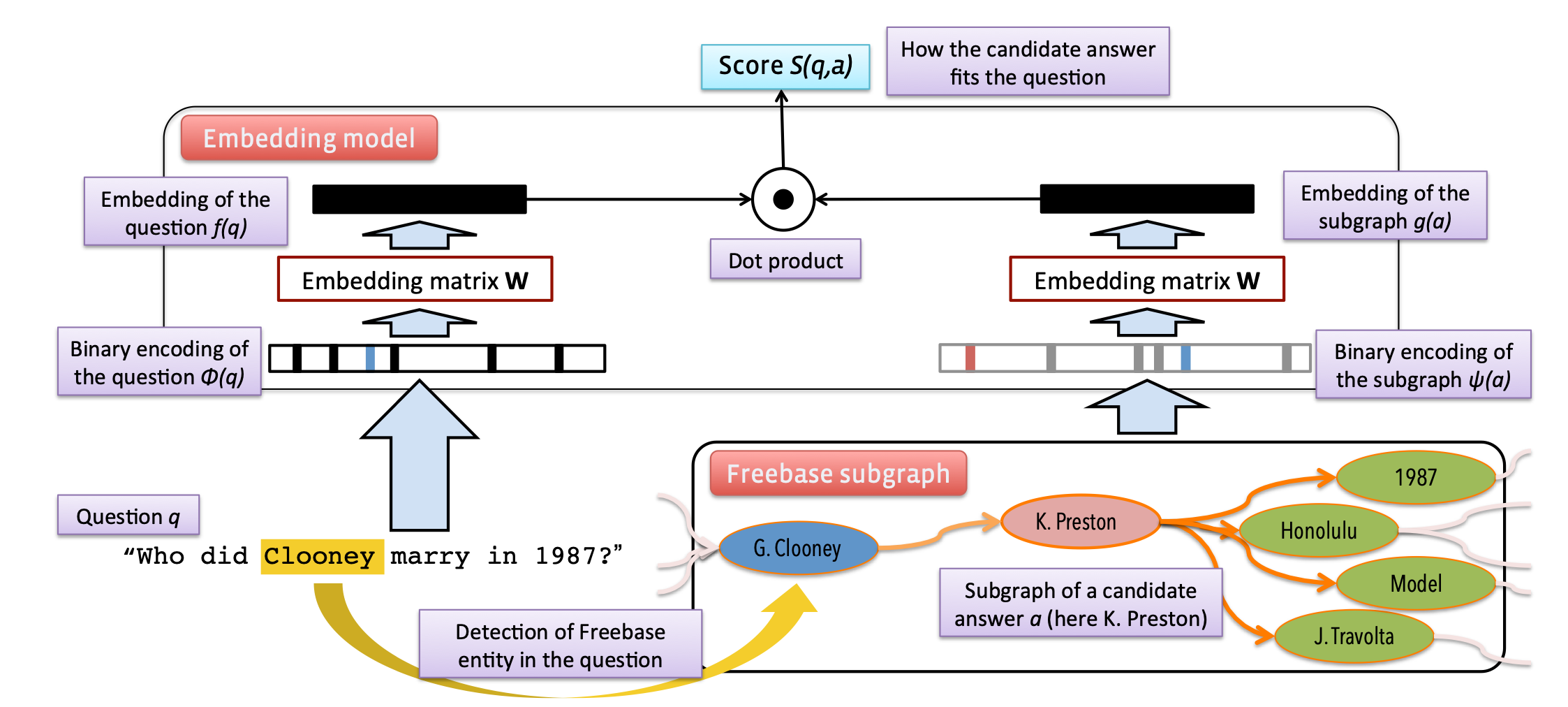
上图展示了该工作的主要方法。如图所示,此方法主要包含问题嵌入与子图嵌入两个分支。
为了获得问题的嵌入,该文使用了同一种稀疏统计表示方式,即统计问题中每个单词的词频,从而得到与整个词表大小相同的稀疏统计向量表示:\(\phi(q) \in \mathbb{N}^N\),其中\(\phi(q)\)为问题的稀疏统计向量,\(N\)为整个词表(包括单词\(N_W\)、知识库中的实体和关系\(N_S\))的大小。 接着,通过一个可训练词嵌入参数矩阵\(\textbf{W}\),获取问题的稀疏统计向量的低维稠密的文本嵌入表示: \[ f(q)=\mathbf{W} \phi(q) \]
作者对答案的嵌入表示\(g(a)\)提出了三种方案:
(1)实体嵌入:与问题嵌入的方式相同,直接通过实体 one-hot 在共享的词嵌入参数矩阵中获取对应的嵌入: \[ g(a)=\mathbf{W} \psi(a), \] 其中\(\psi(a)\)为与\(\phi(q)\)类似的稀疏统计向量,会将答案以\(N_S\)维的稀疏向量表示,\(g(a)\)为获得的实体嵌入(即答案嵌入)。如果一个问题存在多个答案,则直接对多个答案的嵌入表示求平均。
(2)路径嵌入:该工作会考虑最多两跳的答案路径。例如对一个两跳的答案路径:(barack obama, people.person.place of birth, location. location.containedby, hawaii)中的头实体、尾实体和路径上的所有谓词都使用\(\psi(a)\)进行嵌入。
(3)子图嵌入:对一个答案,在一跳或两跳的范围内构建子图,对这个子图中包含的实体和关系同样使用\(\psi(a)\)进行嵌入。但为了区分答案路径与子图中实体和关系,作者对\(N_S\)设定了两倍的大小,子图和路径的嵌入分别使用不同的部分。
通过上述的方法分别获取问题的嵌入\(f(q)\)与候选答案的嵌入\(g(a)\)后,可以对它们进行相似性评分: \[ S(q, a)=f(q)^{T} g(a), \] 然后使用hinge loss损失函数进行训练: \[ \sum_{i=1}^{|\mathcal{D}|} \sum_{\bar{a} \in \overline{\mathcal{A}}\left(a_{i}\right)} \max \left\{0, m-S\left(q_{i}, a_{i}\right)+S\left(q_{i}, \bar{a}\right)\right\} \] 其中\(D\)为训练集,\(q,a\)分别为问题和答案,\(m\)为 margin,\(\bar{a}\)为\(q_i\)的负样本。最小化该损失函数可以达到让问题与正确答案的打分尽可能大,让问题与错误打分的打分尽可能小的目的。
实验证明,这篇论文提出的方法在 WebQuestions 数据集上得到了优秀的结果。对比实验也发现,使用子图嵌入来作为答案的嵌入比其它两种方式效果更好。