XGBoost 算法万岁!

机器学习算法的新女王将接管整个世界……
(本文与 Venkat Anurag Setty 共同完成)
我还记得 15 年前我的第一份工作。那时,我刚完成研究生课程,作为一名分析师加入了一家国际投行。在入职的第一天,我小心翼翼地工作,不断回想学过的知识,心里想着自己是否能胜任这个企业的工作。老板感受到了我的焦虑,笑着对我说:
“别担心!你只要了解回归模型就行了!”
我仔细想了想,“明白了!” —— 无论是线性回归还是逻辑回归我都了解。老板是对的,在我的任期内,专门构建基于回归的统计学模型。我并不是孤身一人,因为在那时,回归模型是无可争议的预测分析女王。15 年后,回归模型的时代结束了,这位老女王已经退位。新上任的女王有着时髦的名字:XGBoost 或 Extreme Gradient Boosting。
什么是 XGBoost?
XGBoost 是一种基于决策树的集成(ensemble)机器学习算法,使用了梯度提升(gradient boosting)框架。在非结构化数据(如图像、文本等)的预测问题中,人工神经网络效果好于其它所有算法和框架;然而,在解决中小型的结构化、扁平化数据时,基于决策树的算法才是最好的。下面的图表展示了近年来基于树的算法的演变过程:
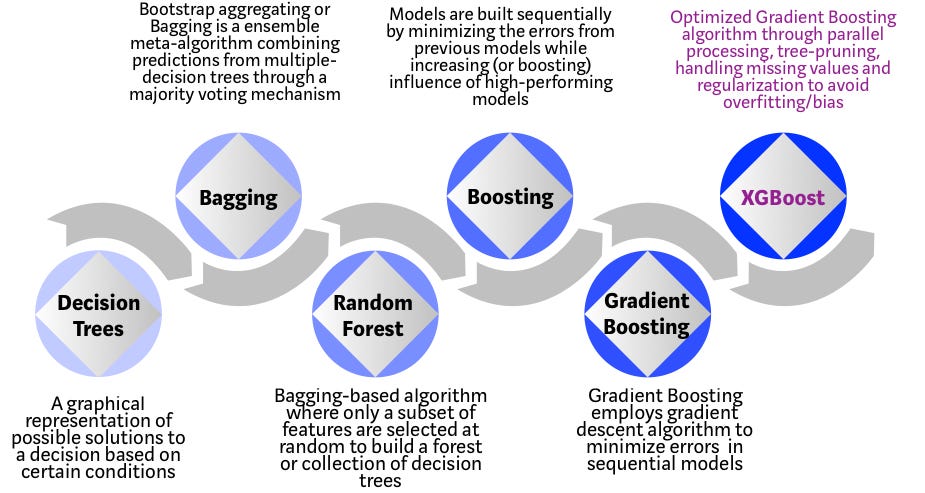
XGBoost 算法是华盛顿大学在科研工程中开发的。陈天奇与 Carlos Guestrin 在 SIGKDD 2016 上发表了他们的论文,迅速吸引了机器学习界的注意。自从 XGBoost 推出以来,它不仅在许多 Kaggle 竞赛中获得了胜利,还为一些顶尖的业界应用提供了动力。因此,形成了一个强大的数据科学家社区为 XGBoost 做贡献,目前 GitHub 上的 XGBoost 项目有 350 余名贡献者,3600 余条 commit 记录。XGBoost 算法还在下面几个方面极为出众:
- 应用广泛:可以用于解决回归、分类、排序和其它用户自定义的预测问题;
- 可移植性:在 Windows、Linux 和 OS X 系统中都能顺畅运行;
- 语言:支持包括 C++、Python、R、Java、Scala 和 Julia 等全部主流编程语言;
- 云端集成:支持 AWS、Azure、Yarn 集群,并与 Flink、Spark 等生态系统配合无间。
如何直观地理解 XGBoost?
决策树在最简单的形式下,是最易于可视化以及最具可解释性的算法,但想要直观的理解新一代的基于树的算法可能会有些困难。可以用下面的类比来更好地了解基于树的算法的演变。

设想你是一名 HR,要对几名优秀的候选人进行面试。而基于树的算法的演变过程的每一步,都可以视为是面试过程的一个版本。
决策树(Decision Tree):每个 HR 都有一系列标准,比如学历、工作年份、面试表现等。一个决策树就类似于一个 HR 基于他的这些标准来筛选候选人。
Bagging:假设现在不只有一个面试官,而是有一个面试小组,组中每个面试官都有投票权。Bagging 和 Bootstrap 就是通过一个民主投票的过程,将所有面试官的输入聚合起来,得到一个最终的决定。
随机森林(Random Forest):它是一种基于 Bagging 的算法,关键点在于随机森林会随机使用特征的子集。换句话说,就是每个面试官都只会用一些随机选择的标准来考验候选人的任职资格(比如,技术面值考察编程技能,行为面只考察非技术相关的技能)。
Boosting:这是一种替代方法,每个面试官都会根据上一个面试官的面试结果来改变自己的评价标准。通过利用更加动态的评估过程,可以提升(boost)面试过程的效率。
梯度提升(Gradient Boosting):Boosting 的特例,用梯度下降算法来将误差最小化。比如,咨询公司用案例面试来剔除不太合格的候选人。
XGBoost:可以认为 XGBoost 就是“打了兴奋剂”的梯度提升(因此它全称是“Extreme Gradient Boosting” —— 极端梯度提升)。它是软件和硬件优化技术的完美结合,可以在最短的时间内用较少的计算资源得到出色的结果。
为什么 XGBoost 效果这么好?
XGBoost 和梯度提升机(Gradient Boosting Machines,GBM)都是集成(ensemble)树方法,原理都是用梯度下降架构来对多个弱分类器(通常是 CARTs)进行提升(boosting)。不过,XGBoost 通过系统优化与算法强化在 GBM 框架上进行了改进。
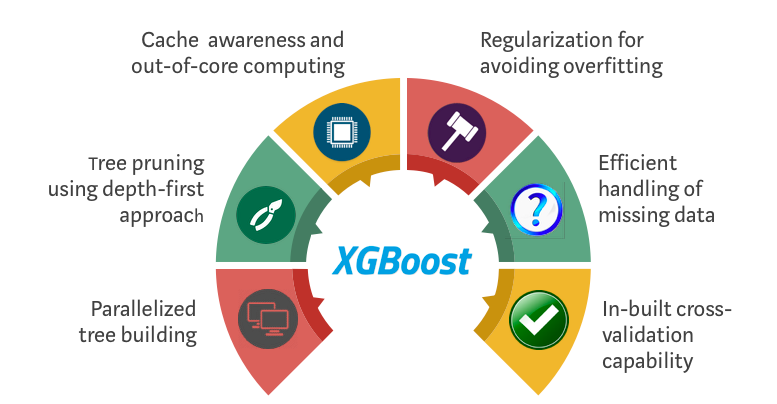
系统优化:
并行化:XGBoost 通过并行化方法来实现顺序的建树过程。由于基础学习器循环内部(包括用于枚举树的叶子节点的外部循环,以及用于计算特征的内部循环)的可互换性,因此才能这么做;循环的嵌套会限制并行化,因为如果没有完成两个开销更大的内部循环,就不能开始新的外部循环。XGBoost 算法通过使用并行线程对所有实例进行全局扫描和排序来进行初始化,使得循环的顺序变得可交换,从而减少了运行的时间。这样做,可以抵消并行化开销而提升算法性能。
树剪枝:在 GBM 框架中,树停止分裂的标准本质上是贪婪的,取决于分裂点的 loss 值。而 XGBoost 用
max_depth这一参数而非某个指标来停止分裂,然后开始反过来对树进行剪枝。这种“深度优先”的方法显著提高了计算性能。硬件优化:XGBoost 算法就是为了高效利用硬件资源而设计的。它为每个线程都分配了内部缓存区,用于存储梯度统计信息。另外,利用“核外计算”方法,在处理不适合放在内存中的大数据切片时,进一步优化磁盘可用空间。
算法强化:
正则化(Regularization):XGBoost 同时通过 LASSO(L1)与 Ridge(L2)正则化惩罚过于复杂的模型,从而避免过拟合。
稀疏意识(Sparsity Awareness):XGBoost 会根据训练 loss 自动“学习”输入中的缺失值,从而自然地接收稀疏特征,并更高效地处理各种稀疏模式(sparsity patterns)的数据。
Weighted Quantile Sketch:XGBoost 使用分布式 weighted Quantile Sketch 算法,可以有效地找到大多数带权数据集的最佳分割点。
交叉验证(Cross-validation):算法内置了在每次迭代时进行交叉验证的方法,不再需要显式地去搜索与指定一轮训练中所需的 boosting 迭代次数。
Where is the proof?
我们使用 Scikit-learn 的 Make_Classification
数据包,创建了一个包含 100 万个数据点、20 个特征(其中包括 2
个信息性特征与 2
个冗余特征)的随机样本集,并用它测试几种算法:逻辑回归、随机森林、标准梯度提升和
XGBoost。
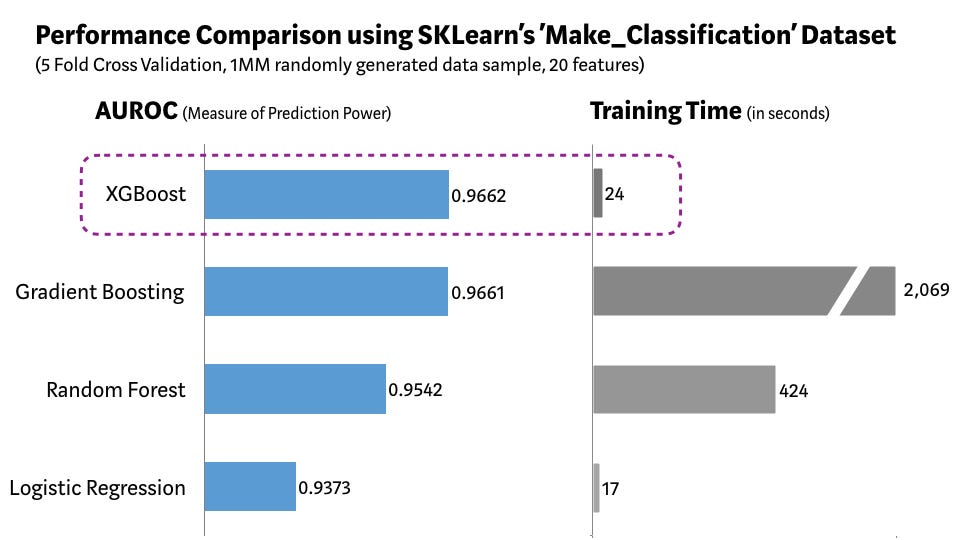
如上图所示,与其它算法相比,XGBoost 模型得到了最好的预测性能与最短的处理时间。研究发现,在其它严格的基准测试中,也能得到类似的结果。因此,XGBoost 在最近的数据科学比赛中被广泛采用,也是意料之中的事。
“当你举棋不定的时候,用 XGBoost 就对了” —— Avito Kaggle 上下文广告点击预测大赛冠军 Owen Zhang 如是说。
我们是否可以在任何情况都用 XGBoost?
在机器学习中(或者说在生命中),没有免费的午餐。作为数据科学家,必须为手头数据测试所有算法,以找到效果最好的算法。但是,选出正确算法还不够,还必须要为数据集正确地配置算法的超参数。此外,在选择最优算法时,除了效果还要考虑其它的因素,比如计算复杂度、可解释性、易用性等等。这正是机器学习从科学转向艺术的部分,同时,也是魔法发生的地方!
未来会如何?
机器学习是一个非常活跃的研究领域,目前已经出现了各种各样的 XGBoost 的变体。微软研究院最近提出了 LightGBM 梯度提升框架,体现出了巨大的潜力。Yandex 科技开发了 CatBoost,得到了令人印象深刻的基准测试结果。出现一个在预测性能、灵活性、可解释性和实用型都优于 XGBoost 的框架只是时间上的问题。然而,在这个更强的挑战者到来之前,XGBoost 将继续统治机器学习的世界!
掘金地址:https://juejin.im/post/5d484040e51d4561f95ee9de