Support Vector Regression
Intro quote from
“A Tutorial on Support Vector Regression”, Alex J. Smola, Bernhard Schölkopf - Statistics and Computing archive Volume 14 Issue 3, August 2004, p. 199-222
A support vector machine constructs a hyper-plane or set of hyper-planes in a high or infinite dimensional space, which can be used for classification, regression or other tasks. Intuitively, a good separation is achieved by the hyper-plane that has the largest distance to the nearest training data points of any class (so-called functional margin), since in general the larger the margin the lower the generalization error of the classifier.
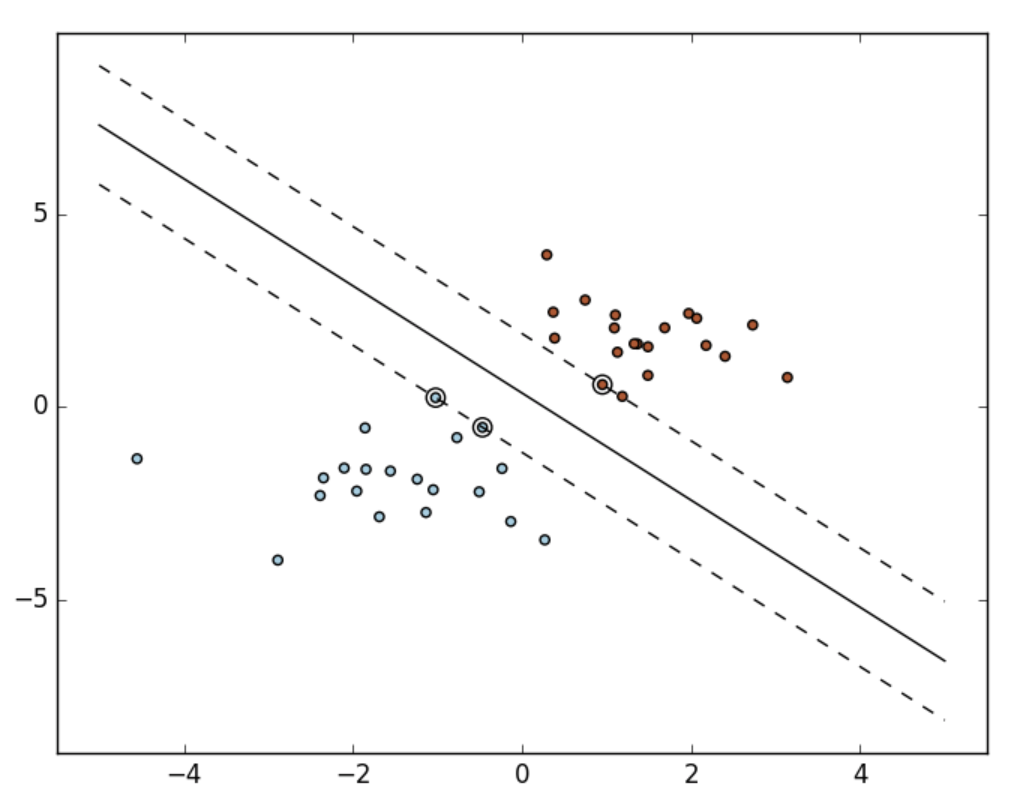
Mathematical formulation
Given training vectors \(x_{i}\in \mathbb{R}^{p}\), i=1,..., n, and a vector \(y\in {1,-1}^{n}\),SVC solves the following primal problem:
\[\min \limits_{w,b,\zeta }\frac{1}{2}w^{T}w+C\sum_{i=1}^{n}\zeta _{i}\\ subject \to y_{i}(w^{T}\phi (x_{i}+b))\geq 1-\zeta _{i},\\ \zeta _{i}\geq 0,i=1,...,n\]
Its dual is
\[\min \limits_{a} \frac{1}{2}a^{T}Qa-e^{T}a\\ subject \to y^{T}a=0\\ 0\leq a_{i}\leq C,i=1,...,n\]
where 'e' is the vector of all ones,'C' > 0 is the upper bound,'Q' is an n by n positive semidefinite matrix,\(Q_{ij}\equiv y_{i}y_{j}K(x_{i},x_{j})\),where \(K(x_{i},x_{j})=\phi (x_{i})^{T}\phi (x_{j})\) is the kernel. Here training vectors are implicitly mapped into a higher (maybe infinite) dimensional space by the function \(\phi\).
The decision function is:
\(sgn(\sum_{i=1}^{n}y_{i}a_{i}K(x_{i},x)+\rho )\)
These parameters can be accessed through the members dual_coef_ which holds the difference , support_vectors_ which holds the support vectors, and intercept_ which holds the independent term