单变量线性回归的预测方程、代价函数与梯度下降
此代码是未进行向量化的
代价函数 1
2
3
4
5
6
7
8function J = computeCost(X, y, theta)
m = length(y); % number of training examples
J = 0;
for i=1:m
J += (theta(1)+ theta(2)*X(i,2)-y(i))^2;
end
J = J/(2*m);
end
梯度下降 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15function [theta, J_history] = gradientDescent(X, y, theta, alpha, num_iters)
m = length(y);
J_history = zeros(num_iters, 1);
for iter = 1:num_iters
k = 0;
o = 0;
for i=1:m
k +=(theta(1)+ theta(2).*X(i,2)-y(i));
o +=(theta(1)+ theta(2).*X(i,2)-y(i)).*X(i,2);
end
theta(1) -= (alpha/m).* k;
theta(2) -= (alpha/m).* o;
J_history(iter) = computeCost(X, y, theta);
end
end
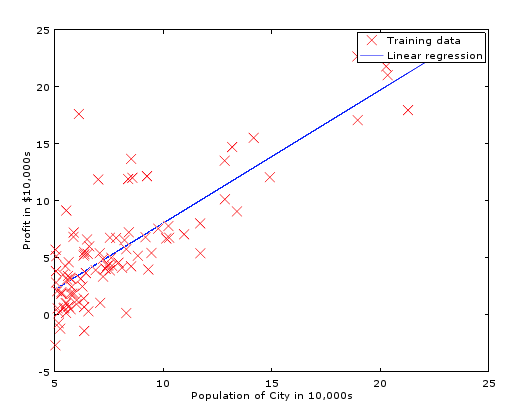
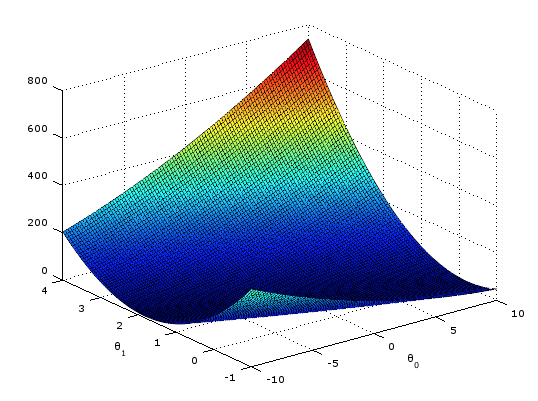
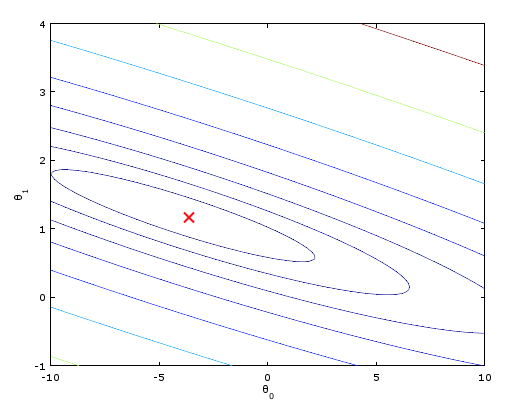
运行结果