机器学习学习笔记(四)
多元线性回归与梯度下降的推广
已经理解并明白了单变量线性回归与其对应的两个参数的梯度下降方程,现将情况推广到多元的情况。
例如最初的例子房价与房屋大小的关系,现在可以加上卧室数量、大厅数量、房屋年龄等其他的参数一并参与考虑来进行预测。
| Size(\(feet^2\)) | Number of bedrooms | Number of floors | Age of home(years) | Price($1000) |
|---|---|---|---|---|
| 2104 | 5 | 1 | 45 | 460 |
| 1416 | 3 | 2 | 40 | 232 |
| 1534 | 3 | 2 | 30 | 315 |
| 852 | 2 | 1 | 36 | 178 |
| ... | ... | ... | ... | ... |
在单变量线性回归中,样本的数量被记作m,在多元的情况下依然记为m,例如上表的数据有多少行m就为多少。
同时上表较之前多了几列,其特征数量即为n,即除了price之外的列数即为n,n=4。
同样将数据分为输入数据x与输出数据y,以m上标n下标的形式表现。例如上表的第三行表示的房子的层数就用\(x^{(3)}_3\)来表示。
因此由原来简单的
\[h_\theta(x)=\theta_0+\theta_1x\]
推广开来,成为了如下形式
\[h_\theta(x)=\theta_0+\theta_1x_1+\theta_2x_2+...+\theta_nx_n\]
为了定义方便,设x0=1,能得到对多元与单变量都适用的预测方程:
\[h(x)=\sum^n_{i=0}\theta_ix_i=\theta^TX\]
同样的,多元线性回归的预测方程也需要有值来评估预测拟合度的好坏,因此引入之前的代价方程,推广到多元情况,很容易得到代价方程(Cost Function):
\[J(\theta_0,\theta_1,...,\theta_n)=\frac{1}{2m}\sum^m_{i=1}(h_\theta(x^{(i)})-y^{(i)})^2\]
对于单变量线性回归来说,梯度下降的原理如下:

而对于多元线性回归来说,\(J(\theta_0,\theta_1)\)推广到了\(J(\theta_0,...,\theta_n)\),因此求偏导得到的结果有n种情况。
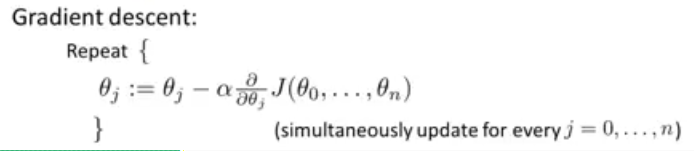
偏导得

\[ \theta_0:=\theta_0 - \alpha\frac{1}{m}\sum^m_{i=1}(h_\theta(x^{(i)})-y^{(i)})x^{(i)}_0\] \[ \theta_1:=\theta_1 - \alpha\frac{1}{m}\sum^m_{i=1}(h_\theta(x^{(i)})-y^{(i)})x^{(i)}_1\] \[ \theta_2:=\theta_2 - \alpha\frac{1}{m}\sum^m_{i=1}(h_\theta(x^{(i)})-y^{(i)})x^{(i)}_2\]
可以发现,最终得到的公式仍然符合单变量线性回归(n=1)。
偏导过程可由高数解出。