机器学习学习笔记(一)
the field of study that gives computers the ability to learn without being explicitly programmed
机器学习让计算机有能力去自主学习,而不是被死板地编程,它发源于人工智能领域,在现在各个领域发挥了独特的作用。
应用示例
谷歌百度等搜索引擎实现的学习算法学会如何对网页排名,从而让海量的网页有序地展示在用户面前;
Iphone等手机与某些app在处理照片时,能够自动地识别出照片中的人;
电子邮箱系统在用户对广告邮件等标记垃圾邮件后,垃圾邮件过滤器学会了如何自动甄选出垃圾邮件,让用户避免垃圾邮件的困扰;
无人驾驶汽车通过图像或雷达等传感器学习大量正常驾驶时车辆的情景从而学会自己安全地驾驶;
在通过对各种棋谱、棋局的研究学习后,下棋软件能够打败世界一流的棋手;
等等...
机器学习的崛起
机器学习的概念在很早之前就已经出现,例如神经元网络在1943年就已经被提出。 现在,网络技术与自动化技术飞速发展, 出现了大量的数据集可以运用与机器学习算法,例如网络企业的点击记录、医院的电子医疗记录、DNA测序等等;甚至机器学习算法已经被应用于探究人类的学习方式,并试图理解人类的大脑。
机器学习算法的分类
监督学习(Supervised learning)
无监督学习(Unsupervised learning)
强化学习(Reinforcement learning)等
一、监督学习(Supervised learning)
包括回归问题(预测)、根据特征参数分类等。
举栗子:
(1)在收集大量关于某地房价与房屋面积的数据后,可以大致判断出房价与面积成线性关系,并能预测出数据中未包含的面积大小对应的大致的房价。
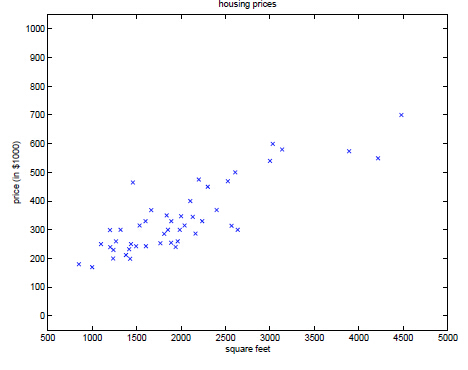
(2)在收集到大量某肿瘤病人的数据(如年龄与肿瘤大小)后,对病人的病情(如肿瘤良性恶性)进行输入,得到相关模型。之后的病人就可以根据其年龄、肿瘤大小直接预测出其所在分类(良性恶性)。
总结:在监督学习中,对于数据集中的每个数据, 都有相应的正确答案,(训练集) 算法就是基于这些来做出预测。例如上面的房价和肿瘤性质。
回归问题即预测一个连续值输出,分类问题即预测一个离散值输出。
二、无监督学习(Unsupervised learning)
无监督学习中没有监督学习数据集的属性、标签等,所有的数据都是一样的。
例如,
(1)聚类算法,在大量的没有明确标签的数据中,一些数据有着类似的特征或结构,通过聚类算法可以自动的找到这些数据中的类型。

例如DNA测序,测到的数值量非常大,不同DNA段可能有类似的功能与性质,通过聚类算法找到它们相似的性质并进
行分类。
(2)鸡尾酒宴问题:当两个人在同时说话时,有多个话筒分别在不同的位置对他们的声音进行采集,得到多个样本。经过算法处理后可以将两个人同时说话的声音分离开来(奇异值分解)。
总结
对机器算法有了大概的认知与了解,对与监督学习与无监督学习的异同有了清楚的认识,能够正确地判断出某例是属于哪一类问题